Continuous Multimodal Learning
- 30 Oct 2024
- 20 Minutes to read
- Print
- DarkLight
- PDF
Continuous Multimodal Learning
- Updated on 30 Oct 2024
- 20 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback
WHITEPAPER
Executive Summary
First-generation TAR (Technology Assisted Review) workflows, sometimes called TAR 1.0, feature supervised machine learning, iterative training on large batches of documents, and statistical evaluation of predictive model effectiveness. These workflows have substantially cut costs for large scale document reviews in litigation, second requests, and related applications. TAR software is now being applied to new tasks in litigation, including analysis of inbound productions and enhanced approaches to ECA (early case assessment). Applications outside litigation have emerged, including corporate investigations, information governance, law enforcement, and national intelligence. These next-generation applications demand dynamic and interactive workflows that exploit multiple text analytics tools. Many document reviews could benefit from new workflows, which have been promoted under names such as TAR 2.0, TAR 3.0, and others. Brainspace 6 introduces Continuous Multimodal Learning (CMML), a text analytics framework to support these next-generation workflows. CMML allows you to pursue lines of inquiry using a range of text analytics tools, and leverage the information discovered across all of them to drive training of predictive models. The result is fast-moving workflows where machine learning accelerates discovery rather than getting in the way.
First Generation of TAR Workflows
TAR software includes a range of text analytics tools, text classification, statistical ranked retrieval (in the guise of concept search in e-discovery), clustering, duplicate and near-duplicate detection, email threading, and communications analysis. Text classification, often referred to as predictive coding in e-discovery, is based on supervised machine learning. In supervised learning, you teach the software by manually coding documents, while a machine learning algorithm produces a predictive model from the coded data. The predictive model then assigns a predictive score to each document indicating its likelihood of belonging to a category of interest. The goal of first-generation TAR workflows, or what some have called TAR 1.0, has been to bring efficiencies to large document reviews traditionally carried out by rooms full of attorneys. Typical examples include responding to production requests in litigation and to second requests in antitrust investigations. Law firms, legal service providers, and corporations have developed a range of first-generation TAR workflows. While varying, these workflows tend to share some or all of the characteristics shown in the first column of Table 1. First-generation TAR workflows have focused on text classification as a tool for either reducing the volume of material to review (culling) or ensuring the most promising material is reviewed first (prioritization). Random samples have commonly been used to estimate the effectiveness of culling, using measures such as recall (the proportion of relevant documents that survive after culling). First-generation TAR workflows, as supported by products like Brainspace’s market-leading text analytics software, have shown their ability to reduce the costs of large scale reviews. Results from statistical sampling have helped convince skeptical courts and litigation adversaries that these cost savings can be achieved while finding as much or more responsive material as traditional manual workflows.
1st Gen TAR Workflows Don’t Meet Needs
Despite their successes, first-generation TAR workflows are not always a good match for emerging text analytics application areas such as corporate investigations, information governance, law enforcement, and national intelligence. Nor are they the best fit for all litigation applications. Tasks such as ECA (Early Case Assessment) and analyzing inbound productions put an emphasis on getting to key information fast rather than finding all documents of a particular type. And while large scale reviews in e-discovery are the canonical application for first-generation TAR workflows, factors such as rolling collections and productions, low richness, and time pressures pose challenges to first-generation TAR even there.
Traditional TAR Workflow Tools
Some downsides of first-generation TAR Workflows for next-generation applications are summarized in Table 1 below.
Tool | 1st Gen Workflow | Downsides in Nex Gen Tasks |
|---|---|---|
Control Sets | The TAR software draws a control set (a large random sample) at the start of training, and users manually code it. The control set is used to estimate richness, track the effectiveness of the evolving predictive model, and choose a cutoff for a classifier. | Manually coding a control set can be too expensive when richness is low or a project is small, too slow in a fastmoving investigation, and too static in the face of an evolving definition of relevance. Statistical estimates of predictive model effectiveness are not needed in all tasks. |
Batching | Large batches of training examples, usually selected by the TAR software, are used in training. This is a natural fit for integrating supervised learning with traditional document review teams and workflows. | Batching may make less sense for a small team using an exploratory workflow. Once a few key documents are found, the project may end, or the topics of interest may change substantially, making previously labeled training batches of little value. |
Separating Training & Review | One team labels training and evaluation data, while a second team reviews documents found by the predictive model. This allows experts with limited availability to train the model, while a large team handles the mass of details of review. | Separating training and review makes less sense for an individual or small team whose goal is to find information, not process every document. |
One of the most common complaints when applying first-generation TAR workflows in these faster-moving applications is that supervised learning is too cumbersome. Manual coding of large control sets and training batches, sometimes consisting largely of irrelevant documents, becomes an obstacle rather than an aid. Instead of quickly reaching key information, users spend too much time and energy training and evaluating the system. In addition, supervised learning, while powerful, is only one of many text analysis tools. Different tools find different types of documents and different types of information, and ideally are used together by a team for maximum effectiveness. Since next-generation applications focus on finding information rather than on processing every document, a workflow centered on batch training and classification of each document is not always the most effective approach.
Some Characteristics Typical of 1st Gen & Next Gen Workflows
1st Gen TAR Workflow | Next Gen TAR Workflow |
|---|---|
Users train a predictive model and use it to cull or prioritize a document collection. Review of those documents happens sometime later. | Users continuously train predictive models as documents of interest are found, and continuously use those models to find more documents of interest. |
One expert or a small team trains the predictive model. A different team reviews documents found by the model. | A single team trains and uses predictive models to find relevant documents. They read those documents in support of a review, analysis or investigation, |
Training uses large batches of documents, often chosen by the TAR software itself. | Training uses documents naturally found during a user search for information, regardless of how they were selected. User knowledge is combined with training data. |
A predictive model is trained until predictive effectiveness stops improving. | Predictive models are trained when convenient, and only to the extent the provide value. |
Workflows are centered around supervised learning. | Workflows integrated multiple analytics tools, any of which can feed supervised learning, and turn in, use its results. |
Evaluation focuses on the effectiveness of the predictive model. | Evaluation focuses on the effectivenss of the overall workflow. |
Large random samples are used to estimate richness, track training progress, and set cutoffs for review. | Multiple approaches are used for management and quality assurance. Random sampling is optional, and often reserved for a final validation check at the end of the process. |
The focus is on appropriate handling of every document. | The focus is on finding the right information fast. |
Each project starts from scratch. | Knowledge is accumulated across projects and applied to other similar sets of documents for instant effectiveness. |
Introducing Continuous Multimodal Learning (CMML)
Industry buzzwords such as TAR 2.0, TAR 3.0, Predictive Coding 4.0, and the like have sometimes brought more confusion than clarity. There are actually a range of new applications where text analytics is needed, and an even broader range of appropriate workflows. Table 2 presents some typical characteristics of these next-generation workflows, and contrasts them with first-generation workflows. However, just as with first generation workflows, not every next-generation workflow is same. Addressing next-generation workflows is therefore more complicated that just finding a single magic algorithm.
In response to next-generation applications, Brainspace has developed Continuous Multimodal Learning (CMML), an integrated set of technologies for supporting flexible, interactive workflows. These tools build on the foundation of Brainspace’s established and market-leading text analytics suite. Given the diversity of workflows appropriate for next-generation tasks, CMML does not impose a single workflow model. Instead it provides a framework for carrying out a range of next-generation workflows, and text analytics tools for accomplishing those tasks and tracking progress.

In developing CMML, our goal was to make supervised learning a natural part of exploring a data set and seeking out key information, without requiring it to be at the center of the workflow. You can teach the system at your convenience and in the course of performing other forms of search, analysis, and review. Then apply the trained predictive models to find documents of interest, while at all times choosing the best analytics tool for each task, and pursuing lines of inquiry in the most natural fashion.
That sounds simple, but seamless integration of multiple tools is never easy under the hood. In developing CMML, Brainspace reexamined every aspect of TAR workflows and the software design that supports them.
CMML Innovations
Brainspace’s CMML framework is based on a range of technical innovations to support creating work product, flexibly using supervised learning and other analytics, and managing projects.
Tools that allow your team to record their findings and integrate information across tools are critical for next-generation workflows. Brainspace CMML provides two powerful mechanisms for this: a tagging system integrated with supervised learning, and a notebook capability for collecting, combining, and reviewing sets of documents.
TAGGING
Brainspace 6 allows you to define tags of interest and link these tags to predictive models. Any time a document is viewed, it can be tagged for topics of interest. You can provide training data for multiple predictive models at once, without leaving a line of investigation. Then, at your convenience, apply supervised learning to the tagged documents to build a predictive model. Since you can define multiple tags and link them to multiple predictive models, you can easily experiment with a range of topics, and pursue or drop them according to the value they provide.
The notion of a “tag” has many meanings in information systems, from hash tags on the Internet to RFID chips in warehouses.
CHOICE TAGS
A choice tag is one that is defined to have a set of two or more values that may be chosen from a menu. Tagging may be slightly slower, but choice tags support several functionalities that single tags do not:

Choice tags can be used to define negative examples for supervised learning.
Starting with Brainspace 6.7, it is possible to add multiple choices, up to 5 positive, 5 negative and 5 neutral.
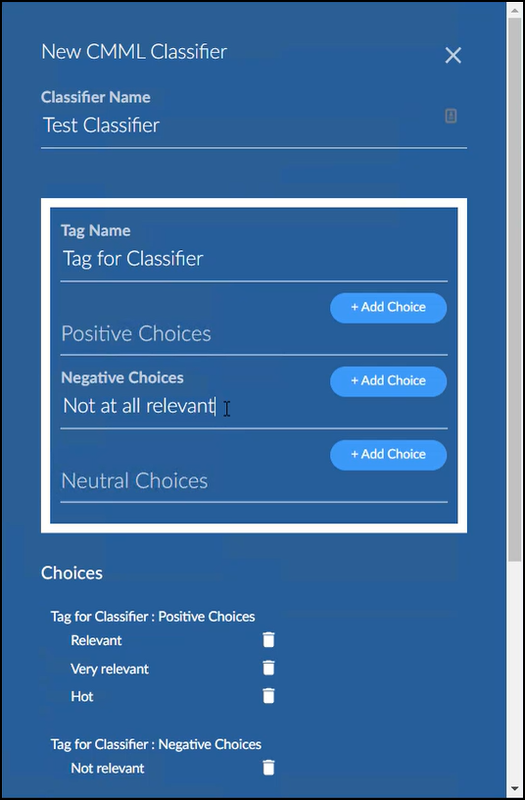
Each positive choice sends the same Yes classification, each negative choice sends the same No, and each neutral choice shows the document has been seen but not classified.
Tags and choices may be renamed.
Only one choice selection is allowed per document.
Choice tags can specify that a document is of interest, but is not to be used in supervised learning. Reasons to exclude a document (permanently or temporarily) from supervised learning include technical difficulties (encryption, bad OCR), need for specialized reviewer (due to technical content or ability to read particular language), ambiguity, or unusual content or format that would lead low quality for training.
Choice tags can be used to verify that all documents in a certain set have been reviewed.

NOTEBOOKS
Even in an interactive and opportunistic workflow, you still need to work with sets of documents. Sets of results must be assembled, work must be coordinated among team members, and it may be necessary to ensure that all documents of a particular type have been reviewed. Notebooks in Brainspace 6 replace Brainspace Discovery’s collections facility. Notebooks enable you to collect a set of documents for easy reference and querying. Add or delete individual documents to a notebook, or build up a notebook in larger increments using queries, clusters, predictive models, or other analytic tools. Tags may be associated with a notebook and tracked, thus supporting a lightweight review capability in Brainspace itself. Conversely, you can collect all documents with a particular tag into a notebook. The set of documents from a notebook can be viewed using Brainspace’s pioneering cluster wheel visualization, and can serve as input to any of the other analytics tools. A notebook can serve as a training batch for supervised learning, so that results from all analytics tools can be used to drive machine learning.
SUPERVISED LEARNING
In first-generation TAR workflows, coding of training documents is done in much the same way that documents are coded in traditional manual reviews. Large batches of documents are selected (usually by the TAR software) and a series of batches are reviewed, with a model trained after each batch, before producing the final predictive model for use. This batch-oriented training process provided a familiar transition from batch oriented manual review workflows.
In next-generation applications, however, you may need to use predictive modeling at any point in your work, and to integrate its use smoothly with other analytics tools. CMML therefore allows predictive models to be trained and used in a much more flexible fashion.
TRAINING WHEN YOU WANT IT
Brainspace’s tagging system makes document coding for supervised learning a byproduct of your work, not an additional step to slog through. CMML accumulates documents as you tag them, and has them readily available when you want to use them to train a predictive model. A predictive model can be trained from as little as a single document of interest.
You can also easily search for and revise your past tagging decisions. This contrasts with some first-generation TAR approaches that make it difficult to change the contents of a training batch or the coding of training documents. The ease of updating tagging decisions eases worries of “getting it wrong” in supervised learning. For instance, you can tag documents broadly while the conception of a topic is still evolving, and then clean up that tagging when the issues at hand become clearer.
The lightweight nature of tagging, predictive model creation, and training reduces the investment to try out new ideas. Tags for different topics, or different versions of the same topic can be defined. Coded documents from previous reviews, which may not be perfectly on point, can be used to kick off training, and then be removed or recoded later after more useful documents are found. You can take a notebook of documents, the results of a metadata search, or a cluster and use to train a throwaway predictive model to find related information.
Freed from the burden of heavyweight processes and fears of making a mistake, supervised learning reaches its potential as an extraordinarily powerful form of conceptual search: a More Like This on steroids.
PREDICTIVE RESULTS WHERE YOU WANT THEM
First-generation workflows tend to isolate predictive modeling from other aspects of text analytics. With first-generation TAR software, you can easily train a predictive model and use it to cull or prioritize a data set. But it can be awkward to examine top-scoring documents, train on them, or explore them using other analytics tools.

In contrast, CMML closes the loop, providing full access to the results of supervised learning within the Brainspace application.
You can rank documents using the score of any predictive model, and then quickly train a new model using top ranked documents. This technique is called iterative relevance feedback, and is a form of active learning often promoted for next-generation workflows (see sidebar). Top-scoring documents can also be batched for later review. Even better, results from predictive modeling can be analyzed using other analytics tools. A particularly powerful strategy is to use Brainspace’s cluster wheel to create a focus on top-ranked documents from a predictive model. This combines supervised learning and unsupervised learning with a highly responsive exploratory visualization tool to explore the most promising portions of a large document collection and turn up new themes of interest.
Document scores can also be used in queries, just like any other metadata. This makes it easy to combine the results of predictive modeling with other criteria to rapidly zero in on the most important documents, and use them with any of Brainspace’s analytics tools.
BATCHES IF YOU NEED THEM
Batching of documents may be less common in next-generation TAR workflows than in first-generation ones, but its uses are actually more varied. CMML provides the necessary support for these diverse uses of batches of documents. You can review training batches within Brainspace itself, using a special review mode that enables one-click tagging of training documents. Batches may also be developed and coded in an external review tool and synchronized with Brainspace. Tags can even be linked with fields in Relativity®. This allows Brainspace to serve as the core analytics function, while an organization’s desired review platform is used for managing review and production. Predictive model scores can be synchronized back to Relativity® as well.
Here are few examples of the ways that batches can be useful in workflows with CMML:
Powering Your Review Tool With CMML: You can manage a large-scale review in your existing review platform, and use the batches of documents coded there for supervised learning in Brainspace. CMML’s predictive modeling can then be used to prioritize documents for the next round of review in the platform. This big batch style of next-generation review is a common alternative to first-generation workflows for large scale reviews.
Filling the Gaps in User-Selected Data: Concerns are sometimes expressed that user-selected training data will miss important subtopics, or even bias the predictive model. Brainspace’s active learning algorithms choose batches of documents not only to accelerate training, but also to fill the gaps in existing training data in an anti-biasing fashion.
Standardizing Supervised Learning: Organizations sometimes develop checklists and workflows for supervised learning as a way to avoid oversights and build client confidence. Other organizations may be required to follow a process negotiated with adversaries in a litigation. A process might specify, for instance, that each of several analytics tools be used to provide a certain amount of training data. CMML’s batching capability (and the progress tracking methods discussed in the next section) make it easy to implement and monitor such processes.
ALGORITHMS
CMML uses the same state-of-the-art supervised learning algorithm as Brainspace’s Predictive Coding (PC) framework, including our multilingual processing and concept formation. CMML additionally allows portable models to be used to kick off training, and metadata fields to be used as features in predictive models, providing additional power. All training batch selection methods, including our Fast and Diverse active learning algorithms, are available for both CMML and PC.
In addition, CMML supports selecting top-ranked untagged documents using the current predictive model and saving those as a notebook for training. This implements incremental relevance feedback, an active learning method invented by J. J. Rocchio in 1965, and recently popularized as “continuous” learning in e-discovery. Incremental relevance feedback is one of the many tools available in CMML for finding relevant documents in a low richness setting.
See our forthcoming white paper Text Classification: The Brainspace Approach for more on supervised learning in Brainspace 6.
TRACKING PROGRESS
In any workflow, managers must be able to track progress toward a goal. In first-generation TAR workflows, the focus is on creating and using a predictive model. Metrics and visualizations are focused on the effectiveness of the evolving predictive model. One example is the depth for recall graph in Brainspace’s Predictive Coding capability.
In next-generation workflows, the goal may be to find most or all documents on a particular topic, much as in a first-generation workflow. However, instead of finding particular information, it might be used to demonstrate that particular information is not present. Different portions of a collection may also have very different review goals. Predictive models, while powerful, are just one of the tools used in accomplishing next-generation tasks. CMML therefore provides a broader range of progress tracking tools than do first-generation TAR systems. These tools include:
Notebook Review: Brainspace allows tags to be linked to a notebook, and tracks progress on reviewing the notebook for those tags.
CMML Progress Graph: This graph tracks the finding of positive documents for the classification against tagging effort.
Validation Sets: You may draw a random sample at any time from all documents that have not been coded as positive or negative for a classification. After coding this sample, CMML will estimate the proportion of untagged documents that are positive examples. This may be done at the end of the project, or at any earlier point, with validation documents recycled for training if the CMML workflow continues.
Supervised Learning: Brainspace 6 supports metrics in both CMML and Predictive Coding that track the training of predictive models:
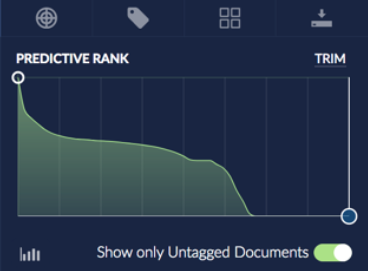
Predictive Ranks: An interactive graph shows the distribution of scores from the predictive model, and allows navigating to particular score regions.
Consistency: A measure of how much the predictive model agrees with the training data.
Classifier Insights: Leverages our portable model capability to track how a predictive model is changing as training progresses.

Not all next-generation workflows need all of these measures. For instance, some workflows are focused on finding a particular type of document within a collection, so the CMML Progress graph is particularly useful. Other workflows require that particular groups of documents have been reviewed, so using notebook progress indicators is helpful. The consistency and stability of the predictive model for a particular classification is useful in understanding the training progress of the model. Multiple analytics tools will typically operate in a CMML workflow, and often several predictive models as well, so progress on training one predictive model from that workflow is only a part of the story.
TARGETED LEARNING
Brainspace supports a powerful mechanism, focuses, for limiting analytics to particular documents of interest. A focus is subset of a data set, produced using any of Brainspace’s analytics tools. A CMML classification can also be limited to a focus, so that training and use of supervised learning is limited to those documents. Restricting CMML to a focus has a range of purposes, including:
Screening out documents known to be uninteresting to speed up training.
Deep dives into particular custodians, time periods, or other groups.
Separating documents by language of origin to build language specific models or aid tagging.
Separating documents by format (e.g. spreadsheets) for special handling.
PORTABLE LEARNING
The first generation of TAR systems treats each project as starting with a blank slate, with a predictive model trained from scratch each time. Users increasingly demand the ability to leverage trained models across multiple projects, and to combine user knowledge with training data, and more generally to be instantly productive on new projects.
Brainspace’s Portable Learning supports these needs. Predictive models trained on one data set can be exported as a portable model in a simple spreadsheet format. The portable model can be manually edited to remove features unlikely to be of interest on new data sets, or to add features based on user knowledge.
The portable model can then be imported into new data sets, providing immediate effectiveness. The imported models can then be tuned to the new data set using supervised learning. Predictive models can also be created from scratch, providing a way to immediately leverage user knowledge.
Portable models provide a way for Brainspace users to build valuable intellectual property that carries across projects and provides ongoing value.
Conclusion
Finding documents once meant keywords and complex query syntax, with all the limitations that brought. Concept search provided a great advance, but still requires effort to understand and balance vocabulary choices.
Brainspace’s CMML is a new approach to finding documents, finding information, and finding resolutions. By making supervised learning as easy to use as search, you may bring its power to bear without specialized training or workflow overhead.
CMML provides the most flexible and efficient way to leverage supervised machine learning for investigations, litigation and intelligence mining.
CMML ENABLES YOU TO:
Focus on the task, not the tool. CMML’s supervised learning lets each new document you find accelerate the pace of locating the most crucial information.
Reduce the time (and cost) to find key information. CMML augments your work without requiring large batches, sampling, or software-selected documents. Portable models allow instant productivity, by accumulating knowledge across projects.
Tailor the workflow to the project. Your team can seamlessly combine the right tools for each project, tailoring them to your working style, and using them all to feed predictive modeling.
Track progress and maintain quality. Tools for tracking progress and measuring quality including optional statistical sampling, support process requirements and management needs.
Brainspace CMML’s support for next-generation workflows complements our Predictive Coding support for more traditional batch-oriented reviews. Look for our forthcoming white paper on Brainspace’s innovations in Predictive Coding, including new visualizations and cost estimation features. Or contact us for a test drive of CMML, Predictive Coding, and the rest of our market-leading text analytic provides ongoing value.