Start seeing sentiment ranking and scores right after dataset building is complete through auto-running models that have been pre-trained by Reveal data scientists. These models are also called system models in Brainspace 6.7 (and newer).
Models included in Release 6.7
The following models are included in the 6.7 release, but more models are planned to be added.
English Profanity. This model will score documents on a normalized range of 0 to 1, with 1 meaning that the model is certain the document contains words considered profane in the English language (including American, British, and Australian English), 0 meaning it does not, and values falling in between scored to hundredths with two decimal points. It would be normal to expect only a small portion of a dataset to be scored highly, that is, at or above .80 as an example relevance threshold.
English Slur. This model will score documents on a normalized range of 0 to 1, with 1 meaning that the model is certain the document contains words considered a slur in the English language, 0 meaning it does not, and values falling in between scored to hundredths with two decimal points. It would be normal to expect only a small portion of a dataset to be scored highly.
Please note that both models are intended for use only on English-language data. If used on non-English data, they may produce false positives (high scores). Such use is not intended or recommended.
Getting the models in your Brainspace instance
The system models noted above will be prepackaged with the release package for Brainspace. You may also be able to add or update a specific system model file to your instance if an updated model is released separately after the 6.7 version.
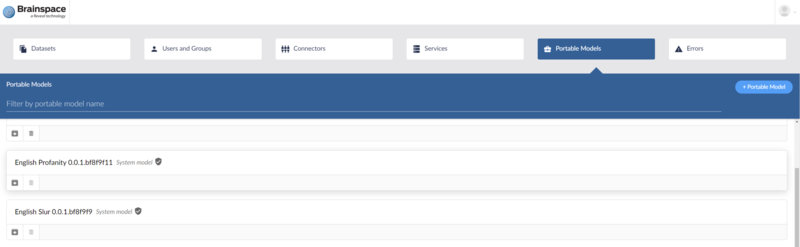
Brainspace Administrators can find a list of system models available under the Portable Models tab of the Administration section. System models will have a special label and shield to distinguish them.
Enabling system models on your dataset
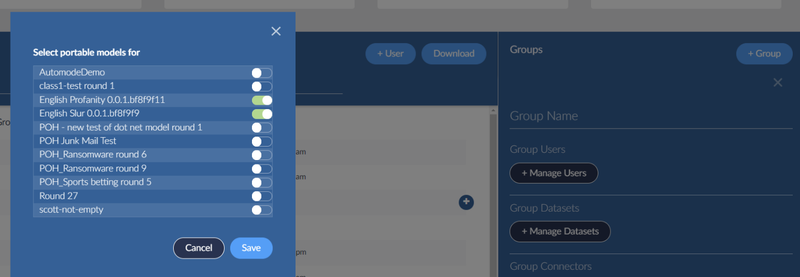
As an Administrator, you can choose which datasets have the ability to use installed system models by turning them on in the Select Portal models panel of the Users & Groups administration area.
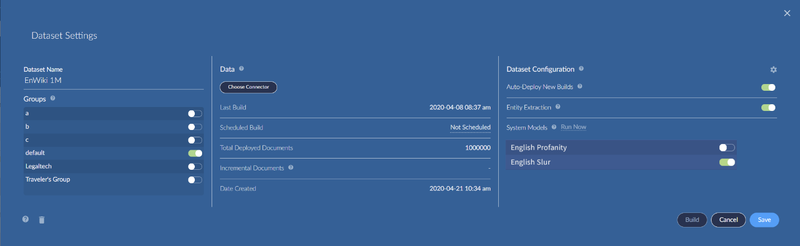
Once a group has access to system models, a Group Administrator (or a System Administrator), can turn models on or off for each dataset in the Dataset Settings.
Building and re-building a dataset to score documents
Pre-trained system models score documents in a dataset at build time. If you enable a new system model to your dataset, a re-build of the dataset will be needed to get documents scored. If you add new data to your dataset, likewise a build will be needed. As with previous versions, builds can be initiated via Dataset Settings.
If you wish to re-run a document scoring process for a dataset, a Run now link is available in the System Models section of the Dataset Settings. It will force a re-scoring of all documents for the enabled (toggled on) system models, and also remove scores from documents for any disabled (toggled off) system models. See Dataset Build Options for more information.
Using system models in your dataset
There are several ways to take advantage of the automatically run pre-trained system models in Brainspace 6.7. You may start using the scores from these models as soon as the dataset build finishes to find high-scoring documents, or you can create your own CMML session based on a system model as a starting point.
There is an important distinction between scoring produced at build time, and that produced by a CMML session you create. There is no way to change the system model score produced at build time by further training. There is a way to continuously update the scores produced by your own CMML session, as CMML normally works, when you start it with one of the system models as a portable model.
On your dashboard
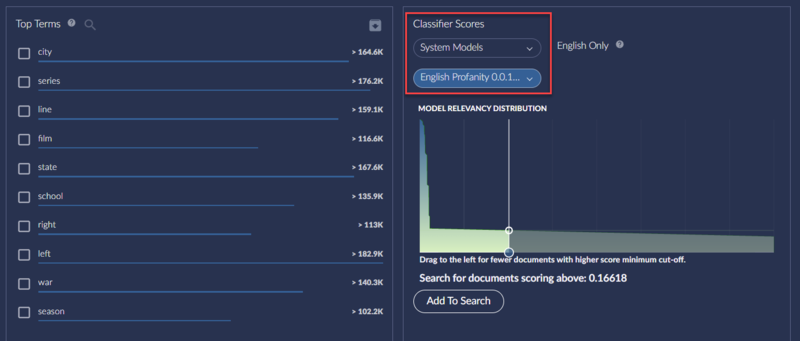
Brainspace 6.7 has a widget to your dashboard for Classifier Scores. The widget displays a distribution graph for one selected classifier and allows you to quickly add a search criterion for a minimum score cut-off by dragging the TRIM line and clicking Add to Search.
The widget displays one classifier at a time. You may select from System Models, if any have been enabled and auto-run on your dataset, or User-Created Models, meaning the CMML classifiers you created. That includes any CMML classifiers, including those you created from a system model as a portable model.
Note
Due to the nature of how document counts are estimated for performance reasons, the graph may project a document count that is not exact or appears off. This might be particularly noticeable on small datasets. It is not ideal but known behavior. Once you search for documents with a given score range, the results returned are exact and not just an estimation.
In Advanced Search
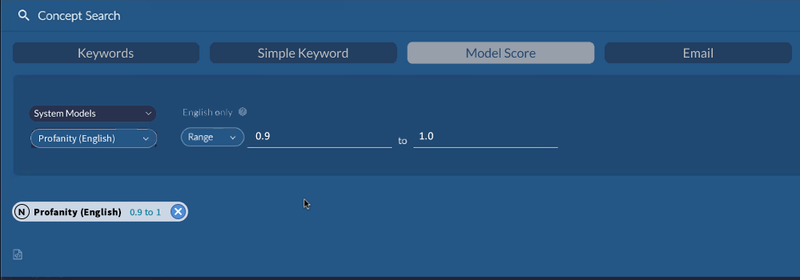
There is a new Model Score tab in Advanced Search. It makes it more convenient to perform a search for documents within a provided score range (normalized 0 to 1). You may select from System Models, if any have been enabled and run on your dataset, or User-Created Models, meaning the CMML classifiers. That includes any CMML classifiers, including those you created from a system model as a portable model. If a CMML classifier hasn’t finished one round, however, you will see a warning message.
The Model Score tab allows you to provide score ranges within the normalized range of 0 to 1. If you wish to perform a raw score search, you can still do that via the + sign in advanced search.
As a portable model
When creating a new CMML classifier, you can select one of the available system models in the Select Portable Model window. System models will have a label and shield to distinguish them.
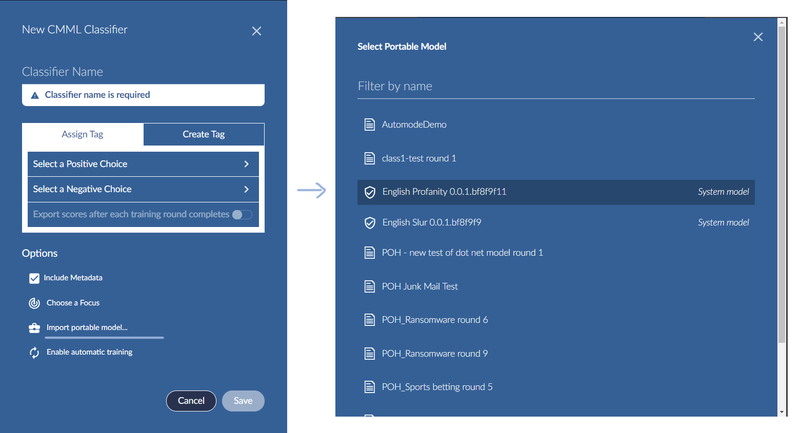
A CMML classifier created in this manner (by importing a system model as a portable model) behave exactly like any other CMML classifier created from a portable model. This means that, among other things, scores for documents may change with every training round of CMML session.
All functions and features of CMML classifiers are available, just note that such a classifier will still be considered user-created when selecting it in some of the model score areas noted previously.
Troubleshooting & Common issues
System model failed. You may see this message in Dataset settings. It indicates that document scoring failed for some reason during dataset build. You can select Run now to retry or perform a new build.
This classifier is not ready to be used yet. You may see this message on the Dashboard. It indicates that document scoring has begun but it not yet finished. Just come back later and refresh the Dashboard.
Some unscored documents in model. You may see this message on the Dashboard. It indicates that there is new or changed data in the dataset, but a fresh build hasn’t yet been completed in order to score all document.
Select classifier with at least one round. You may see this message on the Dashboard when selecting a user-created classifier (CMML classifier). It indicates that the classifier hasn’t gone through one completed round and no scores are available to be visualized yet. Complete the initial training round as you normally would for a CMML classifier and try again.
Document count in graph is off. Due to the nature of how document counts are estimated for performance reasons, the graph may project a count that is not exact or appears off. This might be particularly noticeable on small datasets. It is not ideal but known behavior. Once you search for documents with a given score range, the results returned are exact and not just an estimation.