What is a Control Set
The Control Set serves as a baseline evaluation mechanism against predictive coding results. It consists of a randomly selected set of documents drawn from the entire collection of documents.
Control Set documents usually are coded by domain experts and used for calculating classifier metrics in Reveal AI Supervised Learning. They are regarded as “truth sets” and will be used as a benchmark for further statistical measurements such as:
Precision
Recall
F1
Control Set Creation in Reveal
In Reveal, the user has the option to use the Control Set functionality built into the supervised machine learning module.
The Control Set is a random sample over the entire population of the documents in the data set. As documents are ingested into Reveal, a random ID is generated for each of the documents. The documents are sorted by their random ID and the Control Set is generated by using the top documents. See Table 1 and Table 2 for an example of a Control Set generation process. The Control Set is generated over the entire document collection, this includes exact duplicates.
Table 1 - Random IDs from AI Document Sync
| Table 2 - Documents sorted by random IDs
|
Using Control Set Batches in Reveal
In Reveal, a Control Set is created and extended using Control Set AI batches. The size of the Control Set is not determined when the Control Set is created. Instead, the Control Set is extended as users check out batches of Control Set documents to review.
Control Set and Classifier
Control Set batches are connected to a specified classifier. Users can navigate to the Supervised Learning section and select the card for that classifier to see the Control Set statistics. Follow the link here to view the detailed explanation of Control Set statistics.

Figure 1 - Control Set Classifier statistics
Control Set Batch Creation
A Control Set batch is created when a user
Clicks AI-Driven Batches from the main page,
Selects corresponding Classifier and Tag Profile, and
Clicks SELECT in the Control Set panel:

Figure 2 - Control Set Selection for AI-Driven Batches
This process creates a Control Set batch and assigns the documents in that batch to the reviewer who checked out the batch. The number of documents in the batch depends on Classifier settings. The default batch size is 20.
Control Set batches can be created before, during or after users review AI-driven batches and train the respective classifier. If a document was tagged as part of the AI-driven batch, and at a later point the same document is selected to be in the Control Set, this document will be assigned to be part of the Control Set and will be removed from the classifier’s training set.
Consequently, it will have the following impacts:
The overall Control Set population will be slightly larger than requested. For example, if reviewer requested 20 Control Set documents and one of the documents in the original set of 20 documents is already tagged and in Training set. The system then converts this 1 document to be part of Control Set and adds another document to the CS batch. At the end of batch creation, there will be 21 documents as Control Set of which user sees 20 in the assignments folder.
If there are training documents converted to Control Set, the system will automatically kick off a new training round for the classifier. This is to make sure there is no influence left from the converted Control Set document in the classification model.
Control Set Assignment Folder
Once the batches are created, users can access them from the Assignments folder below. The Control Set batches are using the following naming convention: [Classifier]_Control Set[BatchID]. For example, “AI_Responsiveness_Control Set00001”. Follow the link here to view more explanation of AI batches.

Figure 3 - Number of Documents in a Control Set Assignment Batch
Control Set and Incremental Data Ingestion
If there is incremental data ingestion and additional data is added to the data set each additional document receives a random ID that fits into the space of the previously assigned random IDs. This means that the random IDs for additional documents will be mixed into the random IDs of the previously added documents. This allows the users to keep the Control Set that was created before the incremental data ingestion and to extend the Control Set to appropriately cover the updated collection of the documents in the data set.
Note
Starting from 11.11.04, the gap warning message will show up on the Control Set page if there is an incremental processing, and the processing created records that break the continuity of existing Control Set documents. Review teams should examine the Control Set page after each incremental processing. If a gap message is visible, check out a new Control Set batch to fix the gap.
Control Set Gaps
Control Set documents are supposed to be a contiguous set of tagged documents sorted by their random IDs. In other words, when a set of documents is assigned to Control Set batches, all those documents have to be reviewed in order for the Control Set to be valid and produce valid statistics.
It is possible that not all documents assigned to the Control Set are tagged, this creates a so called “gap” in the Control Set. The documents in the gap must be reviewed before the Control Set becomes valid. The following examples illustrate two possible scenarios that can lead to a gap in the Control Set.
Assume we have ingested 10 documents into a case and reviewer submitted a request to get a Control Set batch that contains 5 Control Set documents. Assume that the random ID for each document is listed in Table 3 (NOTE that Random ID values shown in the tables below are for illustration only and not visible to the user):
Table 3 - Documents are assigned random IDs on data ingestion
Document ID | Random ID |
DOC001 | 20 |
DOC002 | 73 |
DOC003 | 24 |
DOC004 | 92 |
DOC005 | 99 |
DOC006 | 96 |
DOC007 | 19 |
DOC008 | 3 |
DOC009 | 53 |
DOC010 | 21 |
This list is sorted by random ID from low to high and the top 5 docs will be selected as Control Set. Table 4 shows the Control Set documents in the rows highlighted in orange.
Table 4 -Documents Sorted by Random IDs where bold italic is an Example Control Set

If a reviewer reviews all 5 documents in the Control Set (DOC008, DOC007, DOC001, DOC010, DOC003) and tags them as either “Yes” or “No”, then the Control Set will be valid.
However, there are a few possibilities for a gap in the Control Set, including:
Reviewer didn’t review and tag a document from their Control Set assignment. For example, “Doc010” has no tag. This means that the Control Set documents are not fully tagged, this creates a gap containing document “DOC010”. This document must be reviewed and tagged before the Control Set is valid. Table 5 shows an example of a Control Set gap due to a document that has been assigned using an AI batch but not tagged yet.
Table 5 – Control Set Example of Document Missing Tagging from an AI Batch
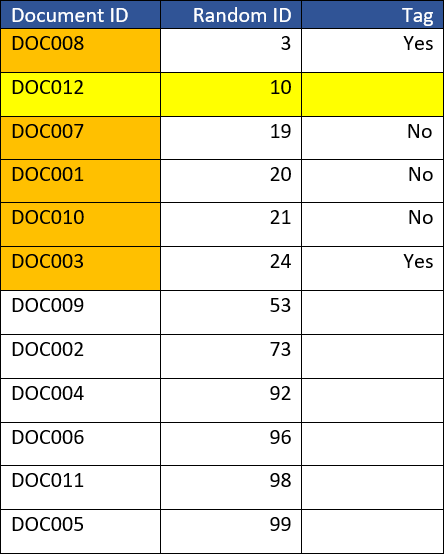
Incremental data ingestion takes place and additional documents are ingested into the same case. For example, 2 more documents were added to the case (DOC011-DOC012). Among them, one of the documents “DOC012” was assigned a Random ID 10, which in the sorted order will be in-between the random IDs of the documents currently selected for the “Control Set”. In this situation the existing Control Set is no longer a contiguous set of documents but has a “gap” containing “DOC012” since “DOC012” is not part of the existing Control Set.
This document must be reviewed and tagged before the Control Set is valid. Table 6 shows an example of a Control Set gap due to a document (DOC012) that has to be added to the Control Set after incremental data ingestion to make the Control Set a contiguous set of tagged documents.
Table 6 - Control Set Example of Gap Incremental Ingestion
The gaps in the Control Set will be automatically detected and the system will stop calculating metrics and show 0 for Precision/Recall and F1. There will be a warning message to indicate a “gap”:
In case reviewer didn’t review and tag a document from their Control Set assignment, the message will be as follows:
“Control Set Has Gaps. Since assigned Control Set documents are not fully tagged, statistics are not available. This can happen if assigned Control Set batches are not fully tagged. Tag all documents in a Control Set batch.”
 Figure 4 - Control Set Gaps Example
Figure 4 - Control Set Gaps Example
In case of Incremental data ingestion, the message will be as follows:
“Control Set has gaps and cannot report metrics. This typically happens on incremental data ingestion. To resolve this, create a new Control Set batch and tag the additional Control Set documents”
 Figure 5 - Control Set Gaps Example #2
Figure 5 - Control Set Gaps Example #2
To fix the gap, the documents in the Control Set gaps must be tagged.
If the gap is due to the documents that are assigned to reviewers using AI batches but not tagged yet, the reviewers must finish reviewing their assignments.
If the gap is due to incremental data ingestion, reviewers should check out NEW Control Set batches as documents in the gap will get assigned to these new batches.
Notice in the incremental data ingestion, the Control Set is NOT automatically extended, the DOC012 will only be assigned to the Control Set when a user checks out a batch. The documents in the gap will only become part of the Control Set when the user checks out a Control Set batch.
If we need to find the Control Set documents that are not tagged yet, search for Documents assigned in the Control Set batches and NOT tagged either “Yes” or “No”:
 Figure 6 - Example Search for Untagged Control Set Documents
Figure 6 - Example Search for Untagged Control Set Documents
Control Set Statistics
Once reviewers finish reviewing all checked out Control Set, the Control Set page will show the following statistics: Precision, Recall and F1. To view details about these statistics, view the online page here.