Brainspace Continuous MultiModal Learning (CMML) analytics can seem uncanny when, after coding a relative handful of documents from a huge dataset, relevant documents bubble to the top. Brainspace is continually learning from classifier coding, and as further documents are assigned and tagged positively or negatively by reviewers, Brainspace can assign rounds of further documents for supervised learning or, as of Brainspace 6.8, autocode models having clean, verified control sets.
In furthering CMML’s efficiency with the implementation of model-based autocoding, Brainspace has placed the following principles front and center:
Transparency – make clear through reporting what has caused a document to be coded as relevant for the tested model.
Reliability – Brainspace autocoding based on the latest round of training will consistently provide the most complete and accurate result.
Human coding is considered over Model scoring.
Control set coding is considered over reviewer training, since this benchmark on which the model is evaluated was reviewed at a high level.
CMML does not consider unscored documents (whether unreadable or empty).
This process replaces a manual workflow instituted after the former predictive coding system was deprecated. This article describes and illustrates how it works.
Preparing a Model for Autocoding
Autocoding may use either an existing model or a model created with a new classifier.
Create a new classifier – under Supervised Learning, click New Classifier.
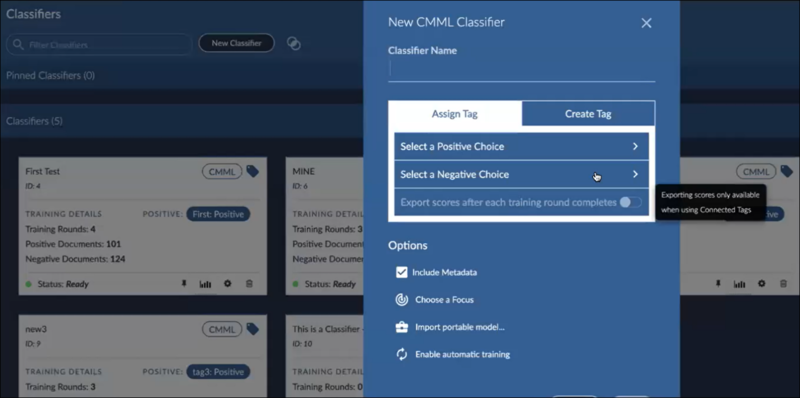
Enter the Classifier Name.
Select a Positive Choice (e.g., Responsive).
Select a Negative Choice (e.g., Not Responsive).
Set Options –
Include Metadata,
Import portable model,
Enable automatic training.
Note
Autocoding requires a control set and control sets cannot be created for classifiers limited to a focus.
Create the tag.
For further background on CMML Classifiers and coding, see Continuous MultiModal Learning.
Create a Control Set for the classifier; a control set is required for autocoding.
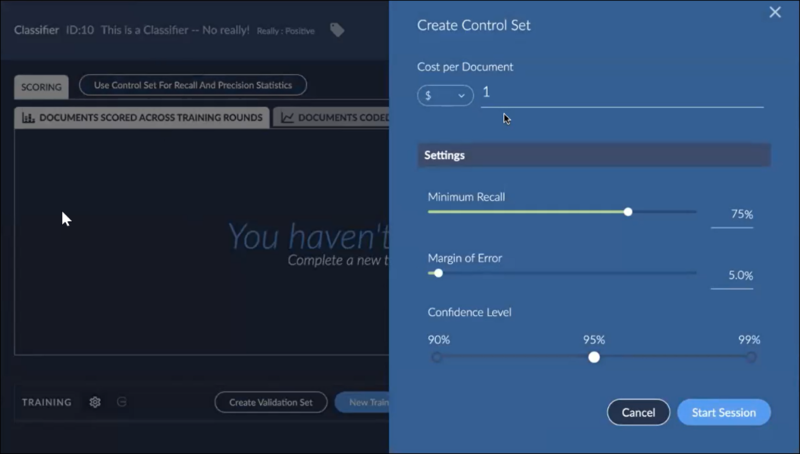
Cost per Document will assign a value to review and training.
Minimum Recall sets the bar for finding relevant entries in the set.
Margin of Error is defined as the range of values below and above the sample statistic in a confidence interval.
NOTE
The number of documents trained in a control set must be sufficient to achieve the margin of error.
Confidence Level establishes the degree of uncertainty allowed the algorithm in determining positive or negative coding.
Train the control set for at least one complete round containing positive (e.g., Responsive) and negative (e.g., Not Responsive) tagged examples. The results will be summarized under Training Statistics for the classifier. Note that the Control Set in the image below contains a note, Additional 14,350 document(s) recommended. Further documents added to and reviewed in the Control Set will clear this message but is not explicitly required to use autocoding.
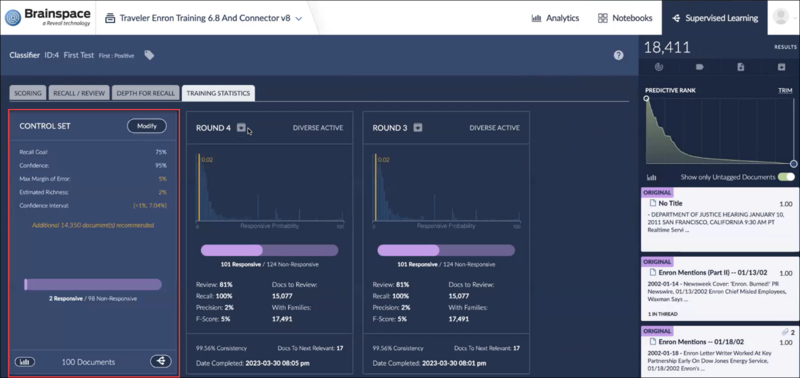
Here is a Control Set panel with sufficient training.
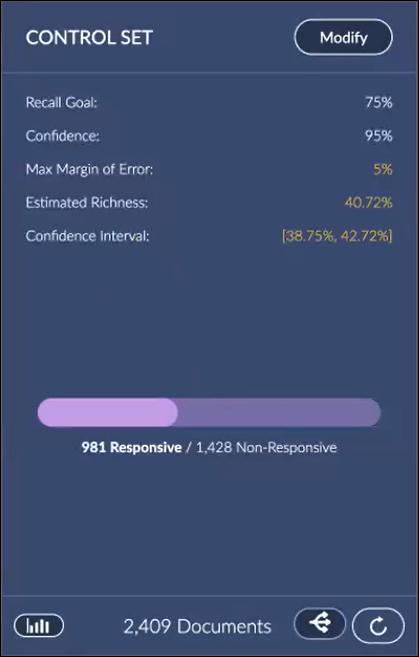
Open Insights and review the model to see if it is working as expected. You will find this in the Training Statistics Summary for the round.

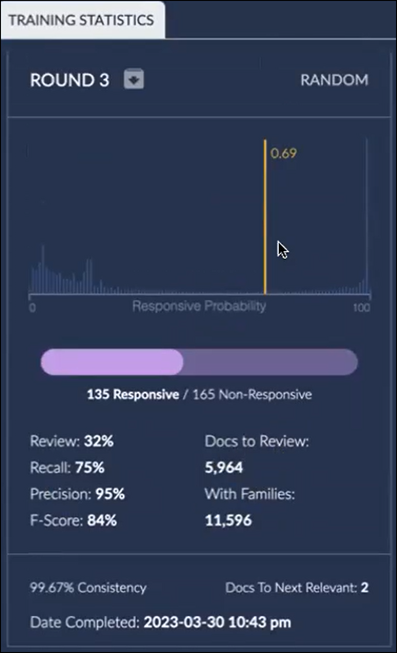
The Control Set may be modified by clicking the Modify button if adjustments are required. The statistics panel below shows a Control Set with a cutoff score changed to 0.69 (69%) Responsive Probability.
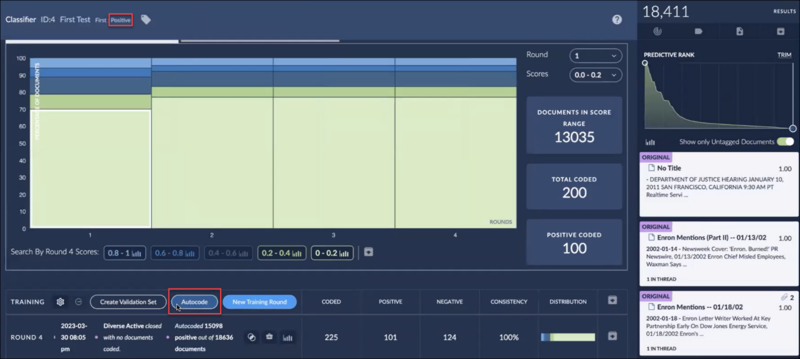
On the Classifier page, at the top of the Training Round table, click the Autocode button.
Review the summary of the number of documents to be tagged as positive (the remainder to be tagged as negative) and the threshold used in the model to generate the autocoding.
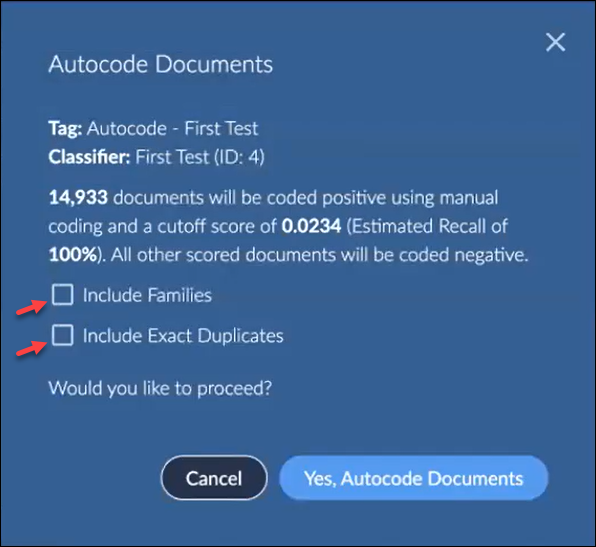
Select whether to Include Families. If selected, you are notified of the number of additional documents to be tagged positive. This will also affect the Precision and F1 scoring, since at least some family members may not be relevant.
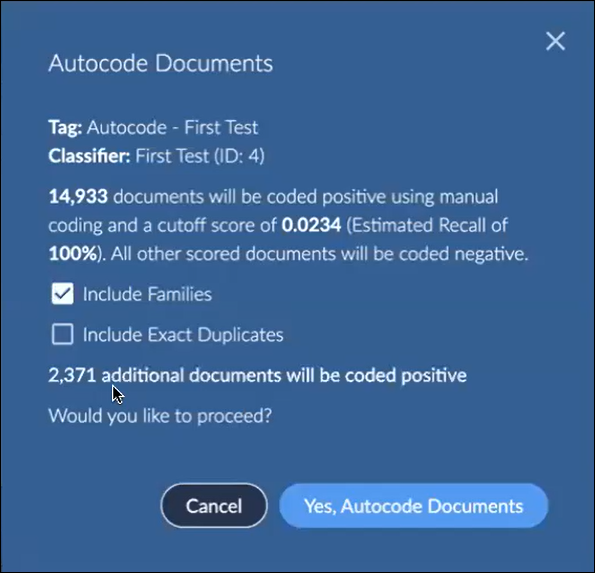
Select whether to Include Exact Duplicates. If selected, you are notified of the number of additional documents to be tagged positive. Exact duplicates share content and basic metadata but may be tagged differently in review based on other factors, such as context or custodian or reviewer interpretation.
Click Yes, Autocode Documents.
View the results for the round by clicking the question mark icon next to the summary results.


Click on the Report menu at the right of the summary and select Autocoding Report to download the report.

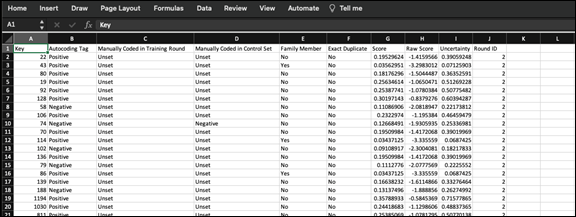
Verify that all documents in the model’s target set have been coded in the round either Yes, No or Unset (for documents that could not be opened or contained no content).
Additional Notes on Autocoding
The control set for the model must contain enough examples to cover the Margin of Error specified.
A training round must be closed before initiating autocoding.
Control sets are required for autocoding models because of the statistical rigor required in a process that generates results with pervasive human intervention. Though control sets entail review (and thus cost) that does not improve the model directly, they do provide a statistical benchmark recognized even in zero trust situations such as contentious litigation.
CMML sessions with multiple positive/negative choices are not supported yet.
Autocoding as of Brainspace 6.8 supports two scenarios:
Brainspace internal modeling and review.
Relativity® connected review – see Relativity® Connected Tags for more information.