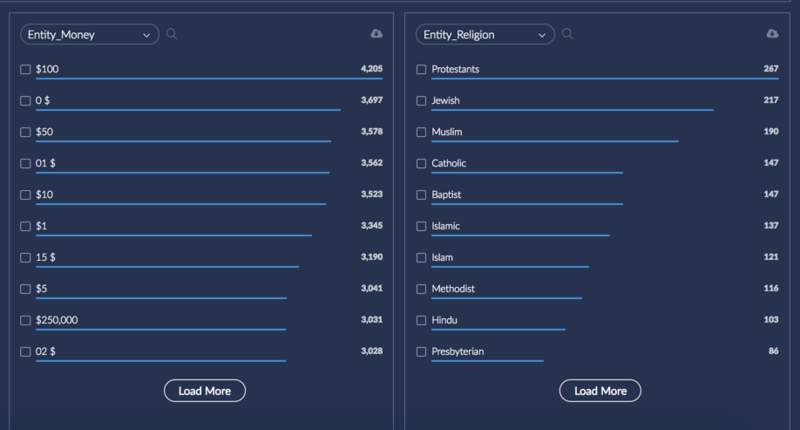
Entity Extraction applies statistical modeling to pick up text from documents such as emails, financial figures, PII, etc. and lists as metadata fields. These fields can be viewed on the Dashboard and gives users the ability to create queries from the terms that were gathered during the analysis phase. Below is an example of faceted lists resulting from the metadata fields, "Entity_Money" and "Entity_Religion."
You have the option of enabling Entity Extraction during the Brainspace ingestion process.
Entity Extraction will automatically identify and extract Entities from the text of your documents regardless of document type as long as text exists.
Brainspace extracts and presents a standard list of Entities within the Facets drop down menu on the Dashboard. Each Entity has a set of unique values identified during ingestion. Each Entity Value will have corresponding document count which represents the number of documents that includes that specific Entity Value.
An Entity Value is specific Entity. Example for Entity_Email a specific Entity Value might be sara_shackleton@enron.com.
The standard list of extracted Entities include:
Entity Field Name (Facets List) |
|---|
Entity_Credit_Card_Num |
Entity_Email |
Entity_Location |
Entity_Money |
Entity_Nationality |
Entity_Organization |
Entity_Person |
Entity_Personal_ID_Num |
Entity_Phone_Number |
Entity_Product |
Entity_Religion |
Entity_Title |
Entity_Url |
Brainspace leverages solutions from Basis Technology for entity extraction.