Introduction
Reveal’s Supervised Learning, as well as Concept Search and Cluster Wheel, supports all tokenized languages. The system automatically handles ingesting documents of different or mixed languages, captures the languages present to enable searching, and prepares them for Supervised Learning.
When training a Supervised Learning classifier on a dataset with mixed language documents, there are several plausible approaches to consider based on project requirements and resources available. These options include creating a single classifier of mixed languages, creating language specific classifiers, or even splitting the data into different projects based on languages.
The approach that is chosen depends on a number of factors that are unique to each project. These considerations include: Are there a large number of documents in different languages? Do some languages have very few documents? Are there documents with multiple languages? Do these mixed language documents use common terminology? Are reviewers multilingual? Is there a need to draw samples and statistically demonstrate effectiveness of each language individually?
In this article, we discuss key considerations and useful features for working with multiple languages.
Workflow Process Flow
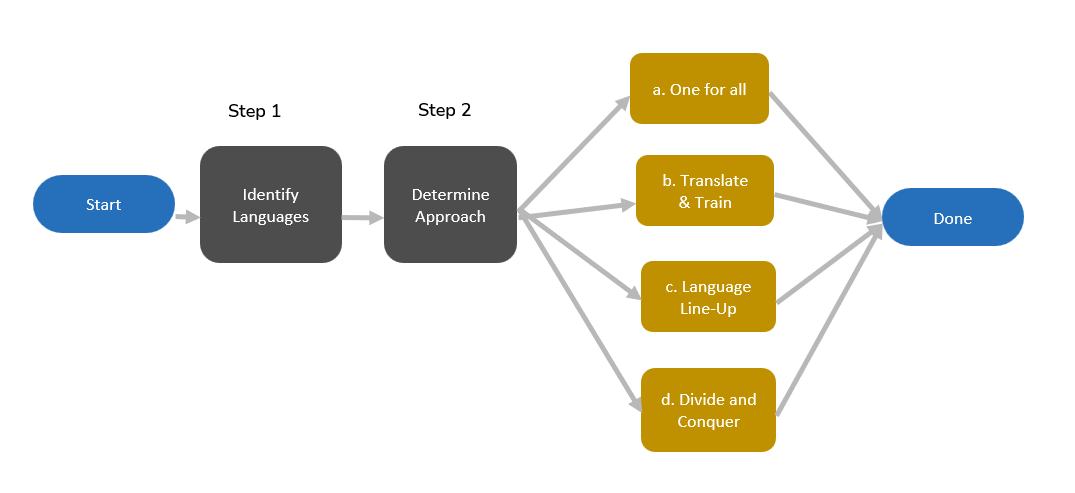
Identify Documents by Languages
During the loading and indexing stages, Reveal detects the languages present in the data. Two key fields—”Foreign Languages” and “BD Primary Language”—can be used to determine if a significant number of documents contain mixed languages. These fields display the identified languages, the percentage of each language, and the number of documents.
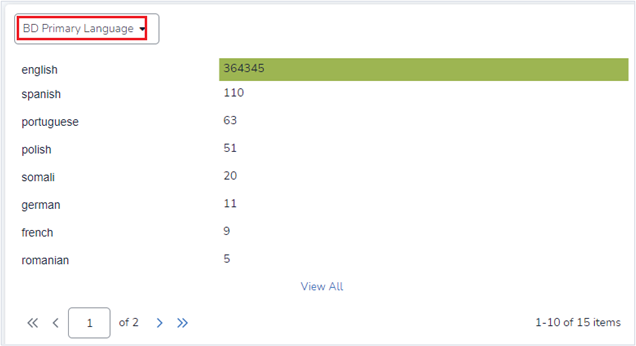
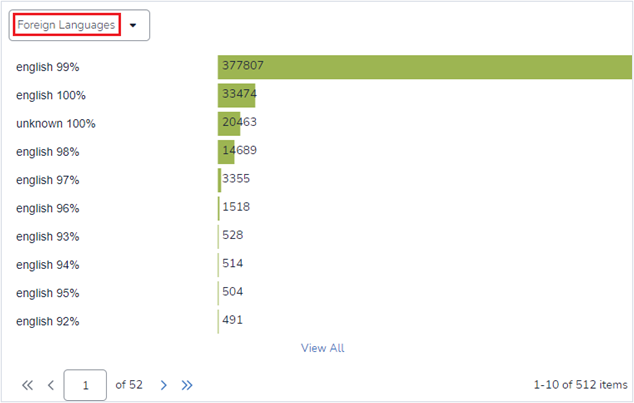
If the percentage of documents in a specific language exceeds a certain threshold (e.g., 20%), you may consider one of the options below. However, this threshold should be adjusted based on project needs. For instance, if identifying documents in a particular language is critical to a Supervised Learning project, lowering the threshold may be beneficial.
Determine Approach
Several approaches have been used to handle multilingual datasets in Supervised Learning. The best choice depends on factors such as language distribution, reviewer availability, and project constraints. Below are four key approaches to consider.
One for all
When alternate languages are minimal or spread thinly across documents, a single project with one classifier may be the most simplest method. This approach keeps all data within a single project while training a single classifier on the entire dataset.
Consider this approach if:
There are no significant numbers of documents in alternate languages (below the threshold agreed upon by the review team).
Alternate languages appear only in small portions of documents (e.g., a document is primarily in English with a minor section in another language).
Time or resource constraints exist, but multilingual reviewers are available.
Key considerations:
Documents from different languages may receive systematically different scores. While ranking within each language may be accurate, the overall ranking may be skewed (e.g., low-quality documents in language A might rank higher than high-quality documents in language B). A solution is to use the ‘BD Primary Language’ field to separate documents and apply different cutoff thresholds per language.
Ensure training documents include all languages. If training is heavily skewed toward the primary language, terms from other languages may not be incorporated into the predictive model.
Translate & Train
When multilingual reviewers are unavailable or resources are limited, translating documents into a primary language before training can be an effective alternative. This approach uses a single project and classifier, with some or all documents in alternate languages translated (typically into English) before training begins. While the predictive model is built on the original text, the translated content assists reviewers during analysis.
Consider this approach if:
There is a significant number of documents in alternate languages, but multilingual reviewers are unavailable, or time and resource constraints prevent training multiple classifiers.
Key considerations:
The predictive model is built using the original language text, not the translation. The translated text is only for reviewer reference.
Translation may add extra time and cost to the review process, and the original text may not always be accurately translated.
Consult your Reveal account manager for cost considerations before submitting a translation job.
For details on how to use translated text for AI, refer to Use Translated or Transcribed Text for AI article.
Language Line-Up
Keeping all documents in one project while creating separate classifiers for each language provides a structured way to manage multilingual data. This approach ensures that all documents remain within a single project, but a separate classifier is created for each language with a significant number of documents in the dataset.
Consider this approach if:
A significant number of documents exist in different languages, and multilingual reviewers are available.
It is important to identify responsive documents in each language.
There is a need to statistically demonstrate the effectiveness of each language individually.
Note
With this approach, AI-driven batches will not be effective.
To train the classifiers, follow these steps and create training batches for each language separately:
Create a saved search for each language to retrieve all documents in that language (using the ‘BD Primary Language’ field).
Refer to Supervised Learning Subset article workflow outlined.
Divide and Conquer
This approach, involves creating multiple projects and classifiers, with documents separated by primary language or a percentage threshold. It is advisable to determine this approach early in the process to prevent redundant data loading.
If a percentage threshold is used, ambiguous or mixed-language documents may be assigned to multiple projects. For example, a document containing 50% English and 50% Spanish could be included in both projects.
Consider this approach if:
A significant number of documents are in other languages, and multilingual reviewers are available.
A Control Set is required.