Introduction
In Supervised Learning, it is common for new data to be ingested after the review team has completed model training and validated it using a Control Set. In many cases, re-training the model is not necessary. This workflow outlines best practices for handling Supervised Learning with incremental data ingestion.
Workflow Process Flow
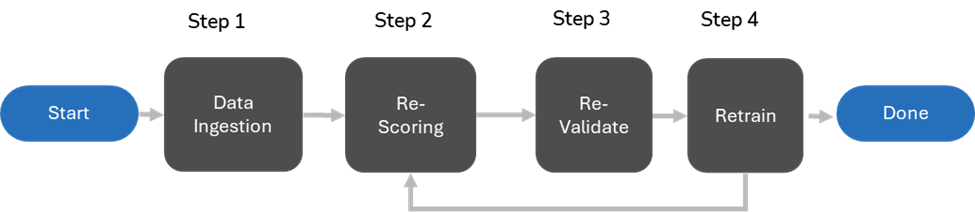
Data Ingestion
The first step in this workflow is to ingest data into the case. Incremental data ingestion is automatically handled by AI sync during the indexing phase. Ensure that the AI sync job completes successfully and that the updated document count in the 'candy' bar meets expectations.
Retrain and Re-Scoring Considerations
Once the data ingestion into the AI system is complete, it is recommended to sample the newly loaded data before initiating re-scoring. Consider retraining the model in the following scenarios:
A substantial volume of new data has been ingested.
The new data significantly differs from the existing dataset. For example, if the original data pertains to accounting, and the new data is from a sales context.
If retraining is deemed unnecessary, navigate to the classifier details page and click “Run Full Process” to initiate the re-scoring process.
Note
Re-scoring will apply to all documents within the case, not just the newly ingested data. To preserve AI scores for documents prior to new ingestion, ensure you export a copy of the AI scores for all documents to a CSV file or transfer them to a new field before proceeding with this step.

Once the data ingestion into the AI system is complete, open the classifier details page and click "Run Full Process" to run the existing model.
 Revalidate
Revalidate
Re-validation is required for two key reasons:
To assess whether the existing model performs well with the newly ingested data.
The number of Control Set documents to add should be proportional to the number of new documents ingested. For example, if the original dataset consists of 1 million documents with 2,000 Control Set documents, and 200,000 new documents are ingested, it is recommended to add 400 new Control Set documents: (200,000/1,000,000) * 2000 = 400
To add the 400 Control Set documents, the reviewer can temporarily change the AI batch size to 400, check out one Control Set batch, and then revert the batch size to its original value.
To determine if the new data has impacted the scores of existing documents.
If elusion testing is used for validation, it’s recommended to repeat the testing against the new data.
Create a saved search to pull a subset of documents from the newly ingested data that are scored below the threshold.
Randomly sample 300-400 documents (using a 95% confidence level and a 5% margin of error) and review them for responsiveness.
Retrain
Wait until the re-validation step is complete, then assess whether retraining is necessary by reviewing the new Precision/Recall values. If the Precision/Recall still meet the team’s requirements, retraining the model is not needed.
Other Considerations
Adding new documents to a case may alter the AI scores of existing documents when the classifier is re-run. If the team wants to preserve the AI scores of documents produced prior to new data ingestion, create a new field and copy the AI scores into it before the new data is ingested.