Introduction
In Reveal 2024, training and validating a supervised learning model are based on the entire population of a case. However, there are instances where the review team may prefer to focus on a specific subset of the data. The article below outlines a workflow for training and validating a model based on a selected subset of documents.
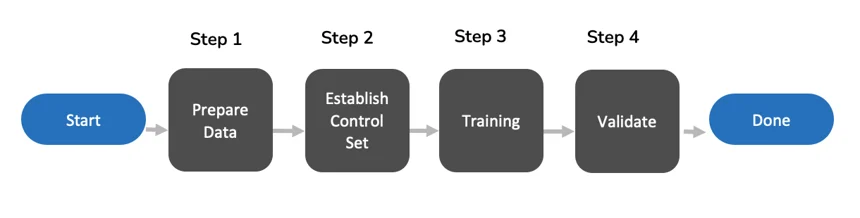
Workflow Process Flow
Prepare the Data
Identifying the project goals is a critical initial step to ensure efficient and effective creation of subsets for classifiers.
Determine Key Issues and Topics. Define the key issues, topics, or themes relevant to the case or investigation. This will help create effective classifiers to identify relevant documents and data subsets.
Set Timeframes and Date Ranges. Define the relevant timeframes and date ranges for the data you need to collect and review. This helps filter out irrelevant data and focus on the period of interest.
Outline Specific Criteria for Inclusion and Exclusion. Develop specific criteria for what data should be included and excluded from the subsets. This includes keywords, metadata filters, document types, and other relevant parameters.
Define Classifiers and Keywords. Identify the keywords, phrases, and classifiers that will be used to categorize and filter data. These classifiers help create subsets of data relevant to the project goals.
Create the Classifier. The first and most crucial step in creating the classifier is making and saving the document subset. Search the applicable documents using the following options:
Keywords – For additional guidance, go to Search Keywords
Concepts – For additional guidance, go to Search Concepts
Advanced Search – For additional guidance, go to Use Advanced Search
Term List – For additional guidance, go to Create a Term List
Create a search by accessing it from the button at the farthest right in the Search bar. This facilitates adding conditions, fields, and even lists of terms to a search. For additional guidance, go to Advanced Search.
Below is an example of creating a search using the term list functionality: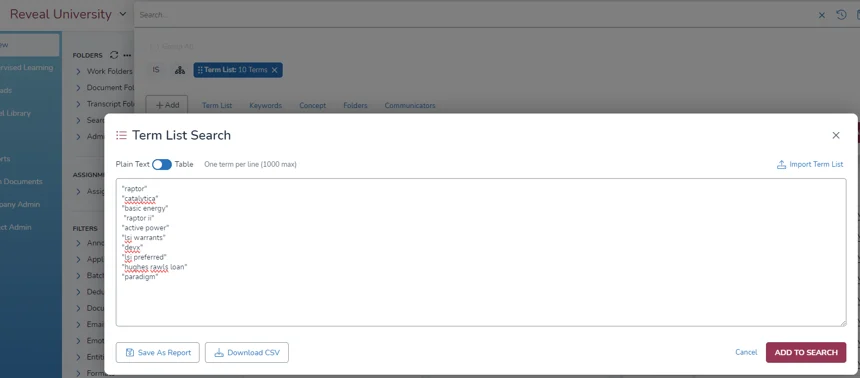
Add Family or Related Documents (optional). You must include family in the search if you want to include family or related documents during the assignment of batches.
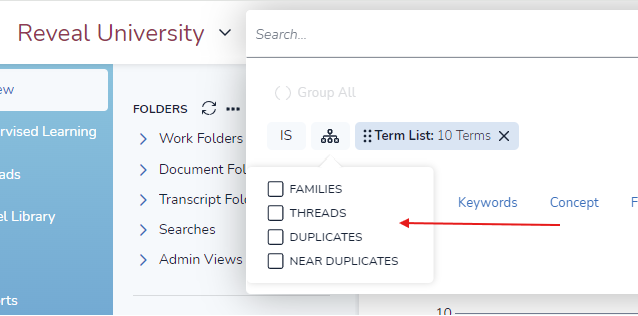
Save the search. Searches may be saved in Search Folders and re-run as needed. Search Folders may be created on the fly for personal use or be shared with another user or team. Once a search is entered, it may be saved using the Saved Searches button at the right of the Search Bar. For additional guidance, go to Saved Search.
Establish Control Set (Optional)
A control set is essential in creating a baseline for evaluating effectiveness and ensuring the accuracy, reliability, and defensibility of automated tools and classifiers' performance. By comparing the control set to the results of your automated review, you can measure key metrics such as recall (the proportion of relevant documents identified) and precision (the proportion of identified relevant documents).
If Precision/Recall is required, to ensure accuracy and avoid using the same documents for both training and validation, it is recommended to establish a control set prior to training when using this workflow. For additional guidance, refer to the knowledge base article Control Set Explained.
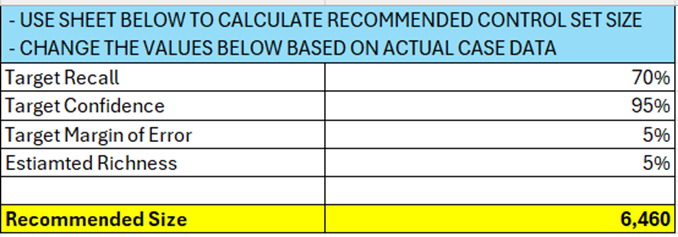
Determine proper Control Set Size
Since this is a subset of the total population of documents, the AI batching for Control Set functionality cannot be used in the platform. Instead, obtain a “Control Set Worksheet” template from Reveal support and use it to calculate the recommended Control Set size. The calculation requires providing the target recall, target confidence, target margin of error, and estimated richness (see an example below).
Create Control Set
Use the sampling function to pull desired sample documents from the document subset.
Execute the saved search to ensure that the subset of documents is available in the grid to perform the sampling.
Click Sample on the Grid Toolbar.

In the first tab, approve selecting the subset documents from the saved search.
In the Sample Options tab, choose by Count and enter the recommended size from the control set worksheet.
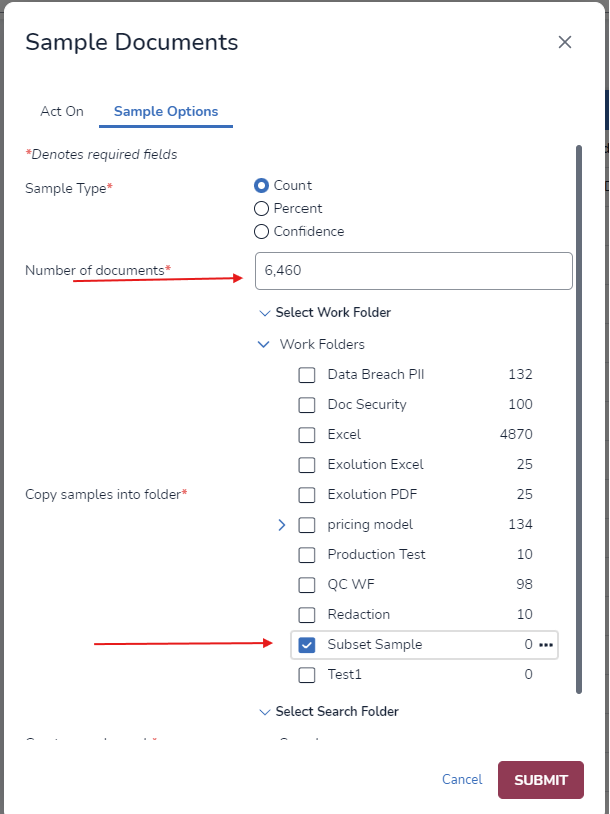
For additional guidance, see Sample Document Set.
Create a dedicated “Control Set Doc” tag with one “Yes” choice:

Run a bulk update on the control set documents to update the value to “Yes” for the Control Set Doc tag for all and only the control set documents. For guidance, go to Bulk Tag Documents
Prepare for Control Set Review
To avoid training the classifier with the control set documents.
Update the saved batch to remove the control set documents.
Retrieve the saved search.
Add NOT (the control set documents).
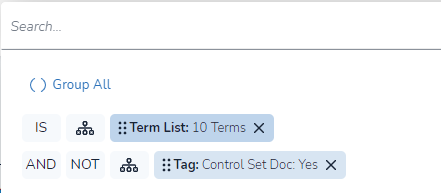
Create a new tag for Control Set review. Use the “Control Set Doc” tag created in step 2 and set a tag rule to prevent the tagging of a control set document during training later.
For example, create the following tag for Control Set review:
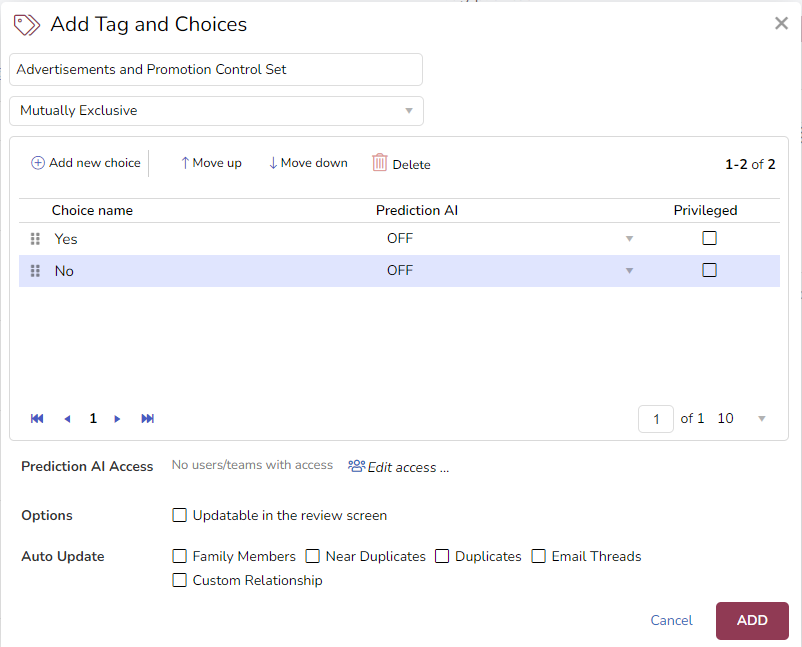
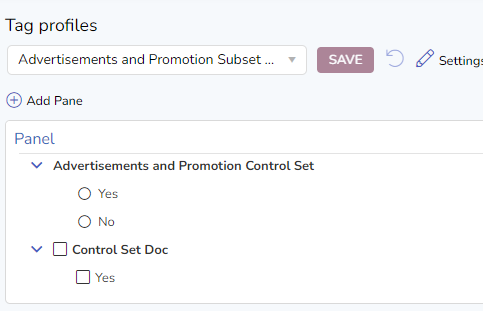
Then create a tag profile with the "Control Set Doc" tag.
Training Considerations
For training based on a subset of documents, consider the following options:
Managed AI Batching
Under this option, reviewers can still leverage the system-recommended AI batching function.
Since the built-in AI batching function will pull documents from the whole database, it is necessary to use “Managed AI batching.”
Use the “AI Batches” button to create new AI batches.
Create a search to identify documents that meet all following conditions:
In the newly added AI batches
In the target subset
Not tagged as “Control Set Doc” tag (see step 2 above)
Assign search results to reviewers.
Refer to the AI batching assignment workflow AI-Driven.
Prioritized Review (by score)
Under this option, reviewers will use AI scores to find likely responsive documents for training.
Create a search to identify documents scored above a certain threshold, for example, 80:
Score > = 80
In the target subset
Not tagged as “Control Set Doc” tag (see step 2 above)
Assign search results to reviewers.
Customized Search
Like the two options above, reviewers can also run customized searches and batch them out for training. The documents batched out to reviewers should adhere to the same rule:
In the target subset.
Not tagged as “Control Set Doc” tag (see step 2 above).
Validation Considerations
For validating a classifier trained based on a subset of documents, consider the following steps:
Determine if the Model is ready for Validation
There are various ways to determine if the model is ready for validation. Below are two ways to consider:
Check the Score Distribution chart. Export only scores from the subset documents to a CSV file, then convert the score column to a histogram.
Click Insert.
Click Chart.
In the Insert Chart dialog box, under All Charts, click Histogram.
Click OK.
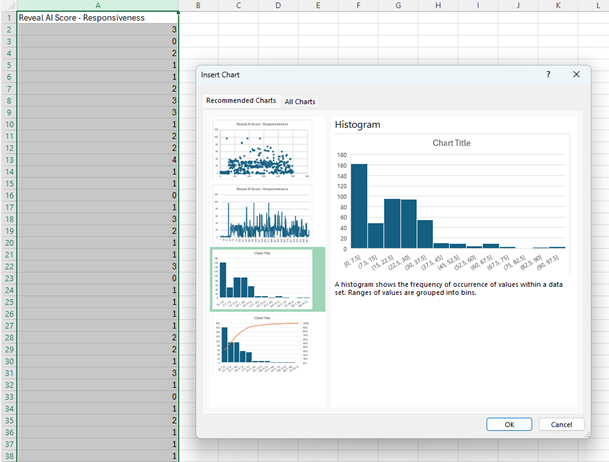
Once the scores are converted to a histogram, examine the chart to determine whether the model effectively categorizes most documents into either the low or high score range.
Calculate the Responsiveness Ratio
If the “Prioritized review (by score)” method above is used during training, the review team can also check the richness of the assigned batches after reviewers finish each round.
The richness can be calculated using the formula below:
Richness = (Responsive documents in the batch) ÷ (Total documents in the batch)
If the richness drops below a certain level (for example, 5%) for a few consecutive rounds, it is a good indicator that the model might have identified the most responsive documents and is ready for validation.
Validate using Elusion Testing
Elusion testing can be conducted against the subset using the following steps:
Create a search with the following conditions:
In the targeted subset
Score below threshold (60% by default, adjust based on need)
Not reviewed for responsiveness
Use sampling function to get sufficient sample size for Elusion testing.
Create a new tag for review purposes.
Assign samples to review team.
Calculate the elusion ratio:
Elusion Ratio
= (Docs in Elusion testing Tagged as Yes) ÷ (Total Docs in Elusion Testing)
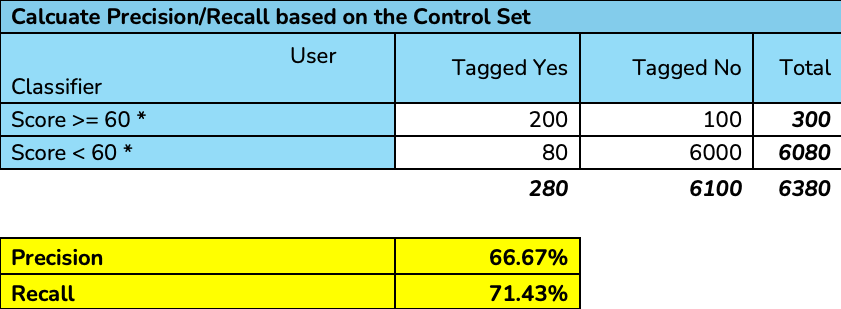
Validate with Control Set
Since the Control Set is already built in Step 2 above, use the Working sheet template provided by Reveal support to calculate Precision/Recall. The required inputs are:
Number of Control Set tagged “Yes” and “Score >= 60”
Number of Control Set tagged “Yes” and “Score < 60”
Number of Control Set tagged “No” and “Score >= 60”
Number of Control Set tagged “No” and “Score < 60”
The score 60 could vary depending on the review team's decision.
Here is an example when using the sheet to calculate: