Review Data Load
Example 1: Load File Mapping Errors
In the example below, there are a number of problems with the load file mapping:
The ITEMID and PARENTID are mixed up.
The CREATION_DATE and CREATION_TIME are mixed up.
The BEGDOC and EXPORTED_NATIVE_FILE location are mixed up.
Once the mapping is saved (or Save As to provide a new name), you can run Preview. In this example, however, an error is flagged before Preview opens:
Once the error is acknowledged by clicking OK the Preview screen will open but display no data.
If we correct the problem with ITEMID and PARENT_ITEMID and save the mapping, Preview will display with no errors because all data fields have been mapped.

Looking at the Preview, however, we can see that even though it reports at bottom No setup errors were detected during preview the Begin Number looks wrong. At load time, the following results might be seen while using Test Mode:


The error log file mentions Truncation and Duplicate key errors.
Data Truncation
In the example, data was truncated when the Native File Path information of 100+ characters was accidentally loaded into the BEGDOC field with a max length of 100 characters.
This issue was first presented in the Error Log with the starting phrase “Data truncated for [Review Field] [truncated data in its entirety]...” 
"…field [Review Field] from [data size] to [max field size], data line [line# in load file (excludes header)], error file [in View Data Errors (includes header)]”. 
The logging has since been improved to provide better guidance as to what fields specifically need to be changed:

If we were to look at the field detail we would see that the BEGDOC field has a max length of 100. Checking the data we see the path is 139 characters long. This explains the truncation. Our solution here is to change the Field to BEGDOC instead of EXPORTED_NATIVE_FILE in our field mapping.
If this were a simple truncation, another possible solution would be to change the Maximum length to something which will accommodate the data size.
Duplicate Keys
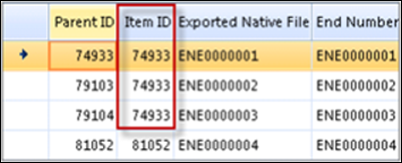
This example also has Duplicate Key Values in ITEMID because the user accidentally loaded Parent ID (attachment information) into that field. This results in 4130 load file duplicates as Parent ID is not unique and Reveal Review requires a unique identifier in ITEMID.

When there are duplicate key values, the software will reference their line in the load file (excluding header). In this instance, errors “Duplicate key value 74933 for column ITEMID on line 2 and ITEMID on line 3” in the error above reference lines 3 and 4 in the load file and preview below.
View of Original Load File

Preview View
View Errors

There is nothing in View Errors for these items as they are skipped at load time and only the first item (original) is loaded.
Date Parsing on Import
There are multiple checks performed and logged during the import of date or date/time format fields. Here is a summary of the factors evaluated and the process used for each. To troubleshoot a date parsing issue, examine the import log file to see how a problem date field has been addressed.
Minimum Date / Maximum Date Allowed
Review system settings ImportMinDateRange and ImportMaxDateRange are first obtained from the Review Manager System Settings if they exist to determine culture-specific settings for the user. If such settings do not exist, the minimum and maximum values allowed by the SQL system are used: these are January 1, 1753 to December 31, 9999. All dates are read from the import data and attempted to be parsed. For all successfully parsed values, a running minimum is saved as well as a running maximum for all values within the programmatically supported SQL range.
Blank Date Strings
Import Profiles can contain a comma-separated list of common Blank Date strings for both CSV and Concordance file formats, which can be used to prevent matching dates in the import file from being validated and imported into the project as actual dates. For example, 00/00/0000, 0000-00-00, 00000000 can be set in the Import Profiles modal’s Blank Date Strings field to filter input from systems that force any of these as a blank date value.

Invalid Dates Count
Tracked as a total running value for each import job.
Date, Time, and DateTime Fields
Import files are checked one line at a time. The data type for each field is used to determine what type of validation is performed on each field.
Common Standard Recognized Formats for US-English Date and Time Parsing
FullDateTimePattern | dddd, MMMM dd, yyyy hh:mm:ss tt | Monday, May 28, 2012 11:35:00 PM |
LongDatePattern | dddd, MMMM dd, yyyy | Monday, May 28, 2012 |
LongTimePattern | hh:mm:ss tt | 11:35:00 PM |
MonthDayPattern | MMMM dd | 28-May |
RFC1123Pattern* | ddd, dd MMMM yyyy HH':'mm':'ss 'GMT' | Mon, 28 May 2012 23:35:00 GMT |
ShortDatePattern | MM/dd/yyyy | 5/28/2012 |
ShortTimePattern | hh:mm tt | 11:35 PM |
SortableDateTimePattern* | yyyy'-'MM'-'dd'T'HH':'mm':'ss | 2012-05-28T23:35:00 |
UniversalSortableDateTimePattern* | yyyy'-'MM'-'dd HH':'mm':'ss'Z' | 2012-05-28 23:35:00Z |
YearMonthPattern | MMMM, yyyy | May, 2012 |
*Time format is 24-hour.
Date Field Data Type
A Date value must not be empty and must not match an Import Profile Blank Date string pattern. Reveal will attempt to parse the date in any recognizable format (see Table 1 above for US-English), ignoring any extra spaces, and will substitute January 1, 0001 as the month, day, and year, if only the time is present. If this fails, Reveal will attempt to parse the supplied value as a YYYYMMDD format. If Reveal was able to parse the value, it will check to see if it is between the allowed minimum and maximum dates; if it is not, the validation will fail.
Time Field Data Type
A time value must not be empty. Time values can be in TotalDiscovery load file format, such as 22:25:47 +0000, but the “+0000” will be stripped before further validation. A format such as 22:25:47 +00:00 is also recognized, and the “+00:00” is stripped before further validation. Reveal will attempt to parse the time in any culture-specific recognizable format (see Table 1 above for US-English), ignoring any extra spaces. An attempt will be made to parse a date, time, or datetime and convert it internally to a full datetime, upon which only the time component will be obtained and used as the validated value. Any errors in the attempt at parsing the supplied value will yield a failed validation on the field and the number of invalid dates count is incremented. If the Null Bad Dates flag in the Import screen is set, the datetime value will be set to null for import record. If the flag is not set, an error will be thrown and the import process will fail.
DateTime Field Data Type
A DateTime value must not be empty and must not match an Import Profile Blank Date string pattern.
If a datetime value is less than or equal to 10 characters in length, Reveal will attempt to parse the datetime in any recognizable format (see Table 1 above for US-English), ignoring any extra spaces, and will substitute January 1, 0001 as the month, day, and year, if only the time is present. If this fails, Reveal will attempt to parse the supplied value as a YYYYMMDD format. If both parsing attempts fail, the date is invalidated and the number of invalid dates count is incremented. If the Null Bad Dates flag in the Import screen is set, the datetime value will be set to null for import record. If the flag is not set, an error will be thrown and the import process will fail.
If the datetime value is more than 10 characters in length, Reveal will first try to remove suffixes such as “+0000” and “+00:00” used in some systems, such as TotalDiscovery load files. For example, "2024-02-12T14:23:24+00:00" would be converted to "2024-02-12T14:23:24" before further internal parsing and validation is attempted on the supplied value. An attempt will then be made to parse the datetime and convert it internally if it matches a recognized standard format (see Table 1 above for US-English). If conversion fails or generates an error, the datetime will fail validation, and the number of invalid dates count is incremented. If the Null Bad Dates flag in the Import Screen is set, the datetime value will be set to null for import record. If the flag is not set, an error will be thrown and the import process will fail.
Regardless of whether the datetime was less than or equal to 10 characters or greater than 10 characters, at this stage, Reveal will check to make sure the obtained value is within the allowed minimum and maximum date range, otherwise the validation will fail.
Nulling Bad Dates and Logging
When both the initial general parsing and any fallback parsing fails for a date, time, or datetime, the supplied value cannot be parsed and imported reliably. If the Null Bad Dates and Log flag in the Import screen is set, the supplied value is set to null and a null value is imported, otherwise an error is thrown and the Import process stops with a failure as it cannot store unknown or invalid values.
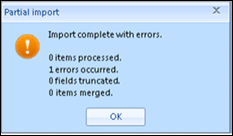
Test Mode Alerts
Some errors are deemed fatal and not worth the time to run a test load to evaluate. Where a necessary value is not found, for example, you might get an error like this:

The solution to this error is suggested in the Alert message: check the template or mapping. Once you click OK to this message, the Test Mode will halt.

Check and validate the mapping to confirm that all necessary fields are properly mapped. Check the template to make sure that all required fields are present.
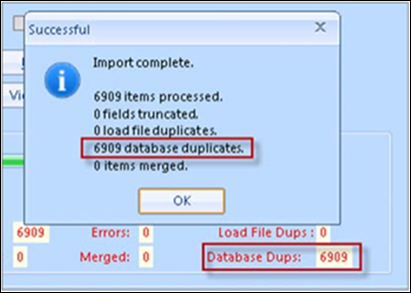
Example 2 – Duplicate Load File
In this example, we have tried to load a duplicate load file. Reveal Review requires unique BEGDOCs. Loading duplicates will result in an error and Reveal Review will not load the documents. If we have duplicate records in the database, Reveal Review will notify on the Status screen.
Error Log

Pop-Up Loading Errors
In addition to the error log errors, you may encounter pop-up errors while loading data which will inform when a data issue is encountered.
Error Message | Meaning | Resolution |
No row at position 1: An Error Occurred. The error description is: There is no row at position 1. | Unable to auto-generate Parent_ItemID, disconnect between fields used to generate the itemid and parent_itemid values. EXAMPLE: Your BegDoc and BegAttach are different, and you are using these to auto-generate: BEGDOC – ENE000001 BEGATTACH – ENRON000001 | Modify the load file data so that the BEGDOC and BEGATTACH are the same. |
String Conversion Error: An Error Occurred. The given value of type String from the data source cannot be converted to type nchar of the specified target column. | The field type and the data are incompatible. EXAMPLE: Error converting a TIME column. Format should be HH:MM am/pm (e.g., 23:09 am; Timezone indicator cannot be included). This is the record that errors: Ϸ2:28:00 (GMT) PMϷ | For this example, you would remove the time zone. |
Header Synch Issue Data error for column [Field Header] on line 1, data error file line 2 Error. | This usually shows up with a DAT file header not being in synch with data. EXAMPLE: Data error for column CC_ADDRESSES on line 1, data error file line 2 error. | This error had a DAT with CC header but no delimited field for CC in the data. |
Reveal ProcessingWithin the Processing Framework, exception-related information is logged to the table [dbo].[Errors] within the project database. Ultimately, the status of a processing task should guide remediation efforts, as the presence of an exception within the database does not necessarily mean that the processing task failed. | ||
Processing frozen at item number # | This error will occur when a container file times out during child extraction due to ‘freezing’ during processing. This is observed at times with PST/ OST/NSF files. This exception is typically due to corruption within the message store. | Remediation efforts should be attempted on the archive. |
Actual/Expected Child Count Mismatch | This error will be associated with a container when the actual generated child count during extraction is not equal to the expected child count collected prior to extraction. Similar to the previous error, this message often indicates corruption within the container. | Remediation efforts should be attempted on the archive. |
Error Importing : 0x80030050… | This is an informative error which indicates that an item identified as an email could not be loaded as an email as is the case with corrupt loose/attached MSG files. | Unless a disproportionate volume of these messages is found, no remediation work is needed and they can be referenced as informative errors. |
UNABLE TO ACCESS SOURCEFILE. FID=###### | This exception will be logged during archive processing of the source archive from the processing repository cannot be accessed. | If this exception is logged, then the presence of the project path needs to be validated. This exception can also be generated when connectivity issues exist between the agent and the processing folder, when temp space is entirely consumed on the agent, or when the source file has been quarantined by antivirus. |
Zero items extracted from email archive | This exception will be logged for any email archive where zero children have been extracted during processing. While this error will be logged for empty PSTs, if this occurs on a PST that is not empty (as can be identified by its file size), it typically appears in conjunction with an additional exception. | |
Child Related Errors | This will occur for NSF files where a child-related error such as an encrypted attachment is encountered. | This can only be remediated by changes to the archive itself (such as applying certificates/user.id etc). |
Note
The native and text file sizes differ from the expanded file sizes. The expanded file size is the size of the text set created.