In addition to the Services and usage reports, many reports are available for each individual dataset. Open Administration from the User menu in the upper right corner of the Brainspace window. Under Datasets select or filter to see the dataset you wish to examine, then click View Reports.
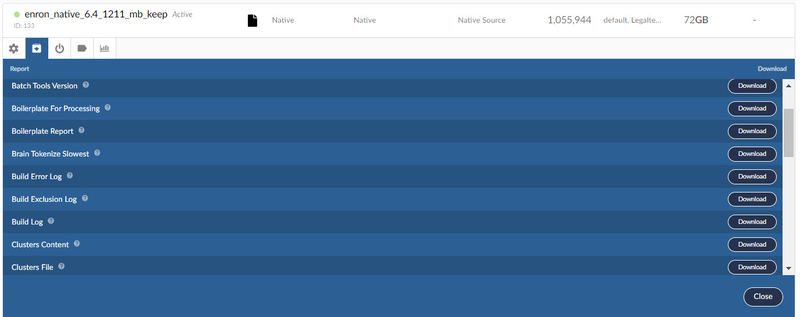
The following reports will be available:
Aliases Report
Provides a list of all the email address aliases within the dataset. (This is generally used by Brainspace, and isn’t a particularly useful report for users. Brainspace recommends using the Person report for alias listings.)
Archive Report
Detailed report of the most recent import or transfer of data.
Batch Tools Version Report
Contains detailed information regarding which Batch Tools version was used to create the dataset, including hostname, mac address, and PID information, as well as history for each incremental build or full build.
Boilerplate For Processing
New in v6.6: Provides a list of all unique potential boilerplate text identified during ingestion.
Boilerplate Report
Provides a list and occurrence count of all the unique boilerplate text identified during ingestion.
Build Error Log
Provides a detailed log of all the build errors encountered during ingestion.
Build Exclusion Log
New in v6.6: Provides a complete detailed log of items excluded during the build process and the reason for exclusion. For example:
pst-2104484-0-af459cd, NoSharedWords
eml-body-a200186, NoSharedWords
Build Log
Provides a complete detailed log of all the ingestion steps during the build process.
Clusters Content
Lists all of the document IDs (for example, Control Numbers) for the ingested documents and maps them to a leaf cluster ID.
Clusters File
Contains the following cluster treeinformation: Cluster ID, Parent Cluster ID, Count of Documents in Cluster, Intra-cluster Metric, Cluster Type, and Folder Name.
Bad Addresses Excluded From Communication Graph
New in v6.6: Reports ingested-numbered documents having bad email addresses and the reason for exclusion.
Communication Graph Domain Index Report
New in v6.6: Alphabetic listing of all unique domains ingested with a cardinal number for each.
Communication Graph Email Index Report
New in v6.6: Alphabetic listing of every unique communicator for emails ingested with a cardinal number for each.
Deleted Documents Report
Log of document IDs for documents deleted from a connected Relativity® workspace if Delete toggle is enabled for Relativity® plus connector.
Document Counts
Provides summary document count statistics for the dataset including how many documents were fed into Brainspace for ingestion, how many were ingested, how many were skipped, number of originals, exact duplicates, near duplicates, etc.
Duplicates Report
New in v6.6: Generates a comma separated value report for each ingested document indicating its duplicate status (Unique, ExactOrig, ExactOrigNearOrig, ExactOrigNearDup, ExactDup, NearDup, NearOrig) and the document to which it is related.
Email Threading Output
New in v6.6: Generates a json output of all ingested data for analysis.
Extended Full Report
Includes all of the overlay fields and values from the Full Report and additional language detection fields BRS Primary Language and BRS Languages.
Full Report
Includes all of the overlay fields and values which can be overlaid into a Third Party system either manually through the review client or automatically by enabling Overlay within the Configuration screen within the Dataset Settings tab.
Import Error Archive
Compressed file that contains one or more of the files that failed to import.
Ingest Error Details
Text report containing more details about the errors in the Ingest Errors report.
Ingest Errors
*.csv report containing errors that occurred during ingestion with the location of the documents that caused the error.
Near Duplicate Detection Output
New in v6.6: Generates a json output of ingested data for near duplicate analysis.
Person Report
List all of the “Persons” automatically or manually created (via People Manager) along with the email addresses (aliases) associated with each person.
Process Report
Summary of the most recent dataset analysis.
Schema XML
The field mapping done via the interface is stored in this file and used to ingest the all of the mapped metadata and text.
Status Report
Summary of the most recent dataset analysis.
Term Document Matrix Key
New in v6.6: A list of ingested document keys.
Vocabulary File
List of all the unique terms and phrases identified within the set of data during ingestion. A weight value identifies how closely or distantly the concept term is related to the dataset’s coded model. Frequency sets forth a count of the usage of the term.