The Analytics Module creates, manages, and deletes Analytics jobs for the project. There are four types of jobs in the module:
Email Threading
Near Duplicates
Patterns
Conceptual Indexing
Each of these jobs provides extended metadata and/or grouping capabilities within unstructured data where similar patterns may not otherwise be found. These values can be used within the Discovery Manager and within the Reveal Discovery Platform.
After the Analytics Jobs are executed within Discovery Manager these added values can be found in Preview and within the Search, Selective Set and Export Modules. Document or excerpt searches can be executed in the Search Module, and Selective Sets can choose to Include Email Threads and Near Duplicates as an option. In the latter case, these items are used as expanders for all line items added to the Selective Set Table. Patterns can be used to isolate files by analyzing these patterns within the Patterns tab underneath the File Properties tab. Preview contains all the fields that are also available within the Export Module Field Load File Options of NDPARENT, NDFAMILYID, NDSIMILARITY, NDNUMCHARS, EMAILTHREADID, EMAILTHREADDIRECTION, EMAILTHREADNUMITEMS, EMAILTHREADINCLUSIVE, CONCEPTTERMS, CONCEPTGROUPS, and CLOSESTCONCEPT.
Note
When Selective Sets are created with the settings Include Email Threads and/or Include Near Duplicates the counts in the line items within the Selective Set table will not reflect the counts for the email threads or near duplicates. These counts will be included when the Selective Set is launched to Preview, or if the Selective Set is used as the scope in other modules such as Reports, Exports, etc.
Within Discovery Manager ECA on the Reveal Discovery Platform, Email Threading and Near Duplicates are used as expanders within Saved Queries, to group files for easier analysis in the Relational List within the Doc View, and as expanders as tagging options. Additionally, conceptual document or excerpt searches can be executed to group conceptually similar documents.
Email Thread Identification
This process evaluates the metadata and/or text of emails to provide the action taken when creating the email (i.e. Reply All, Forward, etc.) and to group emails into their logical threads. Once in their logical thread, additional metadata is created of the total number of items within the thread, and a subset of emails in an email thread that contain all text within the email thread known as inclusive emails.
Email threading can help reduce the amount of time spent reviewing emails by viewing the email conversation as a thread, and/or the inclusive emails within the email thread. Email threading also helps with tagging or coding consistency by using rules to code all emails within a thread consistently.
When evaluating emails for threading the following process is applied to original emails (based on MD5 Hash) in the following order. If an email does not meet the criteria in one process, it will move to the next process. The process applied to a thread is captured in the database to determine which process was applied to the email thread. These values are propagated down to duplicates if other means of deduplication are used at export time (i.e. Custodian Level or No Deduplication).
Outlook Email Threading – This approach is applied to email from Outlook/Exchange, and uses the PR_CONVERSATION_TOPIC and the PR_CONVERSATION_INDEX fields in MAPI to group emails into email threads. This functionality was built into Outlook/Exchange for Office 2013 and later.
Lotus Notes Email Threading – This approach is applied to email from Lotus Notes, and uses the $TUA and $Abstract fields in Lotus Notes to group emails into email threads. This functionality was built into Lotus Notes 8.0 and later.
RFC822 Email Threading – This approach is applied to emails that are not grouped based on the above two approaches and uses the fields Message-ID, In-Reply-To, and References to group emails into an email threads.
Content Based Email Threading – If the above approaches do not work for a given email, content based email threading is used. This approach utilizes a normalized body to group thread members having the same normalized subject. The body normalization process consists of removing all whitespaces, all non-alphanumeric characters, and converting all text to lower case. The normalized text is evaluated for items with the same normalized subject. If there is no match, the email will not be placed into a thread. If there is a match, the file will be placed into the existing email thread.
Near Duplicate Identification
This process evaluates the text of non-email items within a collection to identify files that are very similar in text but not exact duplicate files based on an 80% similarity value. Files are grouped based on a principle or comparison file which is used as the basis of grouping textually similar items together for analysis. This functionality can be very helpful for finding multiple very similar forms of a marketing or sales presentation, quarterly pricing files, etc.
When evaluating files for near duplicate identification the following process is applied to original files (based on MD5 Hash). These values are propagated down to duplicates if other means of deduplication are used at export time (i.e. Custodian Level or No Deduplication).
Text Normalization – The text normalization process consists of converting repeated whitespaces into a single space character, removing all non-alphanumeric characters, and converting all text to lower case.
Near Duplicate Hash Creation – The near duplicate hash is created from the normalized text.
Comparison of Near Duplicate Hashes – Near duplicate hashes are compared using 90% similarity threshold. If there is no match, the file will become the principal file in a new near duplicate group. If there is a match, the file will be placed into the existing near duplicate group.
Patterns
This process evaluates all original items that contain text within a defined scope to identify patterns within the text. Regular expressions provide a powerful, flexible, and efficient method for processing text. The extensive pattern-matching notation of regular expressions enables you to quickly parse large amounts of text to find specific character patterns; to validate text to ensure that it matches a predefined pattern (such as an e-mail address); and to add the extracted strings to a collection to generate a report. Regular expressions are an indispensable tool for many applications that deal with strings or that parse large blocks of text.
Creating Patterns
The Reveal Discovery Manager includes the following system-defined Patterns:
Social Security Number,
Credit Card,
Email Address, and
Phone Number.
When used as part of a Pattern Job, these Patterns will identify files that contain these items within the text. Along with the system defined Patterns, users can create Patterns using the .NET regular expression language. A quick reference guide to the .NET regular expression language can be found by clicking on this link.
There are also many products on the market that help users create .NET regular expression searches which can be found by doing a quick search on the Internet. One that is free and web based is Regex Storm, which can be accessed by clicking this link. While there may be many different tools out on the Internet, this tool is free and has examples of how each .NET regular expression can be used.
Conceptual Indexing
"Latent Semantic Indexing (LSI) is an indexing and retrieval method that uses a mathematical technique called Singular value decomposition (SVD) to identify patterns in the relationships between the terms and concepts contained in an unstructured collection of text. LSI is based on the principle that words that are used in the same contexts tend to have similar meanings. A key feature of LSI is its ability to extract the conceptual content of a body of text by establishing associations between those terms that occur in similar contexts.” (Deerwester et al, 1988)
One great advantage of LSI is that it is a strictly mathematical approach, with no insight into the meaning of the files or words it analyzes. This makes it a powerful, generic technique able to Index any cohesive file collection in any language. It can be used in conjunction with a regular keyword search, or in place of one, with superior results.
Latent semantic indexing looks at patterns of word distribution (specifically, word co-occurrence) across a set of files to determine cohesiveness. In addition to recording which keywords a file contains, the method examines the file collection to see which other files contain some of those same words. LSI considers files that have many words in common to be semantically close, and ones with few words in common to be semantically distant. This simple method correlates surprisingly well with how a human being, looking at content, might classify a file collection. Although the LSI algorithm doesn't understand anything about what the words mean, the patterns it notices can make it seem astonishingly intelligent.
When searching an LSI-indexed database, or a Conceptual Index, the search engine looks at similarity values it has calculated for every content word, and returns the files that it thinks best fit the query. Because two files may be semantically very close even if they do not share a particular keyword, LSI does not require an exact match to return useful results. Where a plain keyword search will fail if there is no exact match, LSI will often return relevant files that don't contain the keyword at all.
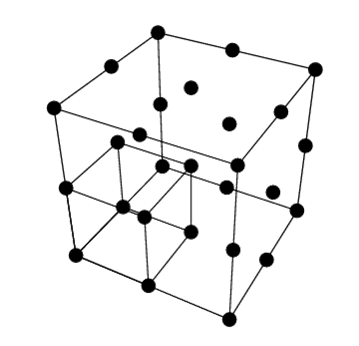
When building an index, a training set of files is used to build or train the index, into which the files are mapped. While this mathematical concept space is many-dimensional, it can be thought of as a three-dimensional space such as a cube or a room as seen below. Each dot below represents a training file. The training set of files enables the Conceptual Index to map searchable files into this space. Files that are closer together in this concept space are inherently more conceptually similar than files that are further apart from each other. All files that have text are searchable, but not all files will be used for training purposes. To see which files are included as training files, please see Appendix B below.
Creating an Analytics Job
To create an Analytics Job, select the Analytics Job Scope and click the Create Analytics Job button in the Analytics Module Ribbon. Then select the Analytics Job Type(s) desired from among Pattern Matching, Near Duplicate Identification, Email Threading and Conceptual Indexing in the New Analytics Job window.
The Reveal Discovery Manager will first isolate the original files within the provided scope(s). Secondly the system will analyze the files to determine if the Patterns that exist in Pattern Management for the project exist in these files. Because of this, it is possible that a scope will yield 0 results when using the provided scope, thus no Analytics Job will be created. If a Pattern is created by the user after a scope has already been used as an Analytics Job, the system will recognize this, and will rerun the newly added Pattern(s) across the scope of data. This allows user created Patterns to be backwards compatible across a given project, but does require that the user create new Analytics Jobs for previously used scopes.
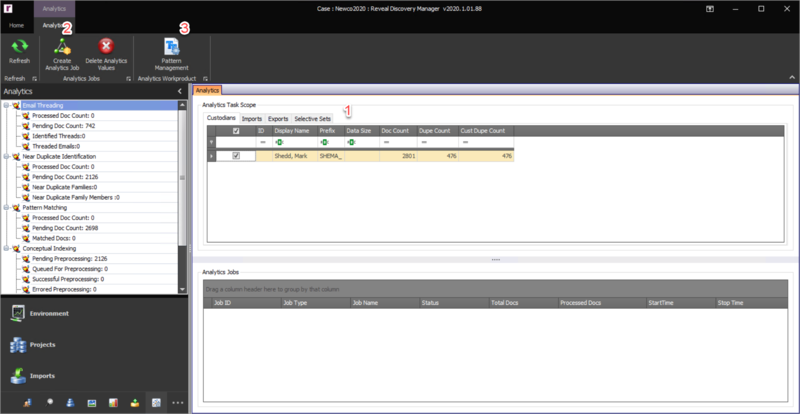
Analytics Job Scope – Select one or more items within a tab by clicking the item’s checkbox
 . Multiple items selected within one tab will be automatically combined with the OR operator when chosen to be part of an Analytics Job. Analytics Jobs can be scoped by Custodians, Imports, Exports or Selective Sets.
. Multiple items selected within one tab will be automatically combined with the OR operator when chosen to be part of an Analytics Job. Analytics Jobs can be scoped by Custodians, Imports, Exports or Selective Sets.Create Analytics Job – After choosing the scope, select one or more items within the New Analytics Jobs form, by clicking the item’s checkbox
 . Each item selected will create a discrete Analytics Job.
. Each item selected will create a discrete Analytics Job.Pattern Matching – Creates a Pattern Matching Analytics Job based on the selected scope.
Near Duplicate Identification – Creates a Near Duplicate Identification Analytics Job based on the selected scope.
Email Threading – Creates an Email Threading Analytics Job based on the selected scope.
Conceptual Indexing – Creates a Conceptual Analytics Job based on the selected scope.

Note
Scopes can be used on rolling bases for new Analytics Jobs. Every time an Analytics Job is created with a scope (i.e. Custodian, Selective Set, etc.), Discovery Manager will only pull back the original files that are within the scope that have not been a part of previous Analytics Jobs. To run Analytics on a scope from scratch, the work product or values for the Analytics Job must first be deleted.
Email Threading can only be performed within projects with data processed in 2016.1.01 or higher.
Pattern Management – Pattern Management allows users to create, edit, and delete custom patterns. To initiate these processes, click the Pattern Management button in the Analytics Ribbon.
Edit Pattern – To edit a user created Pattern, select the Pattern and click the Edit Pattern button.
Delete Pattern – To delete a user created Pattern, select the Pattern and click the Delete Pattern button.
Add Pattern – To create a Pattern, click the Add Pattern button, and the following form will appear. Supply the Pattern Name and the Regular Expression that will be used to identify the files, and click Save.
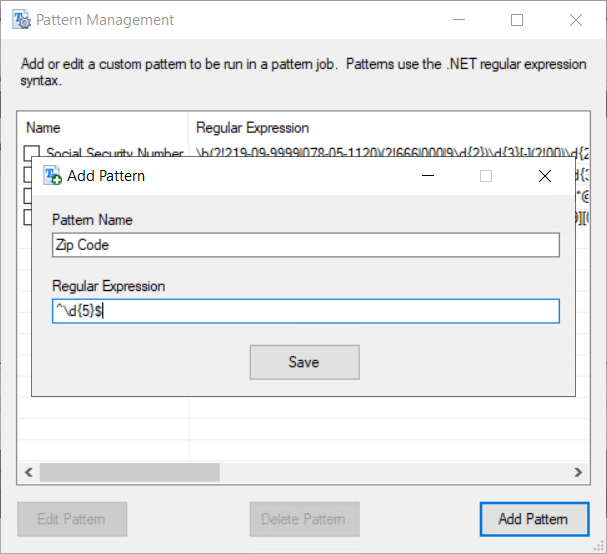
Note
If a Pattern is added to a project after previous Pattern Jobs have been executed on one or more scopes, new Pattern Jobs will need to be executed to reanalyze the scope(s) again for the new Pattern.
Monitoring an Analytics Job
After an Analytics Job is created it is distributed to the Reveal Discovery Agents for processing. To check if a Discovery Agent is running, go to the Environment Module, choose the Processing Machines tab, click the Refresh button, and make sure that one or more machines have TRUE in the Active column. If the all have the value of FALSE, the Discovery Agents will need to be opened on one or all machines. To see more about the Discovery Agents, please see the Environment Module section above. After the Discovery Agents are open, the Analytics Job can be monitored in the Environment, Projects (Processing Jobs tab) or the Analytics Modules. In each Module, the Refresh button should be used, and information regarding these jobs will be updated.
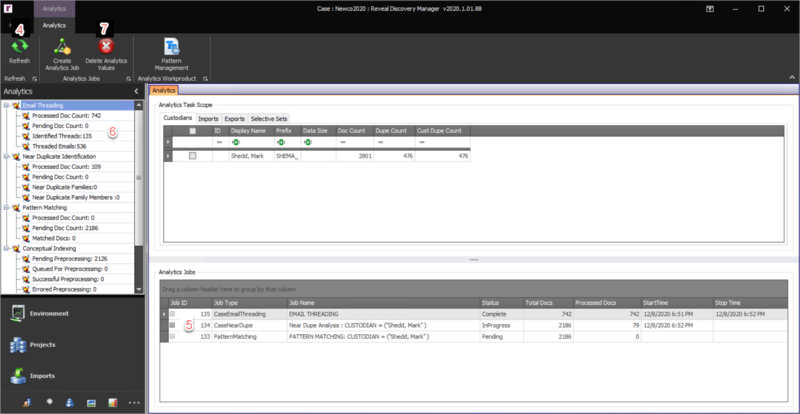
Refresh – After initiating any job, click the Refresh button to see the status of the Analytics Job(s).
Note
After initiating the Analytics Job one or more Discovery Agents must be opened on a machine for the job to start. To see if the Analytics Job is running, click the Refresh button.
Analytics Jobs – This will provide the status of all initiated Analytics Jobs within the project.
Job ID – The ID of the Processing Job.
Job Type – The Analytics Job Type.
Job Name – The name of the Processing Job.
Status – The status of a Processing Job can be any one of the following four values:
Pending – Analytics Jobs that are waiting to be distributed to the Discovery Agents.
InProgress – Analytics Jobs that are currently being distributed out to the Discovery Agents.
Complete -- Processing is complete for this Analytics Job.
Paused – Analytics jobs that have been paused. A paused job can be resumed at any time and will pick back up at the location from where it was paused within the Environment Module.
Total Docs – The total number of files within the Processing Job to be processed.
Processed Docs – The total number of files within the Processing Job which have been processed.
Start Time – The start time of the Processing Job.
Stop Time – The stop time of the Processing Job.
Analytics Module Navigation – Provides the number of docs processed, docs pending, and counts for all Analytics Jobs.
After Creating an Analytics Job
When creating an Analytics Job, the Reveal Discovery Manager will use the provided scope to find all original items that have not been processed for the Analytics Job Type. Because of this it may be necessary at some point to start over for a given scope. Each Analytics Job has a purge button (Delete Analytics Values) within the Analytics Ribbon which will facilitate this process. When selected, all values that have been stored within the project will be removed from the database. If the data are purged for one or all Analytics Job Types, a new Analytics Job should be created for one or all Analytics Job Types.
Delete Analytics Values – To removes the Analytics values or work product from the database, click the Delete Analytics Values button, select one or more items within the Purge Analytics Workproduct form by clicking the item’s checkbox
 , and click OK.
, and click OK.Note
Scopes can be used on rolling bases for new Analytics Jobs. Every time an Analytics Job is created with a scope (i.e. Custodian, Selective Set, etc.), Discovery Manager will only pull back the original files that are within the scope that have not been a part of previous Analytics Jobs. To run Analytics on a scope from scratch, the work product or values for the Analytics Job must first be deleted.
Purging the Near Duplicate Values and rerunning the Near Duplicates Analytics Job can change the principal file. If data has been delivered to a review platform, and these values were being used for further downstream analytic processes, this could change things.